Data warehouse integrations
This article covers how to use Braze Cloud Data Ingestion (CDI) to sync relevant data with your Snowflake, Redshift, BigQuery, and Databricks integration.
Product setup
Cloud Data Ingestion integrations require some setup on the Braze side and in your instance. Follow these steps to set up the integration:
- In your Snowflake instance, set up the table(s) or view(s) you want to sync to Braze.
- Create a new integration in the Braze dashboard.
- Retrieve the public key provided in the Braze dashboard and append it to the Snowflake user for authentication.
- Test the integration and start the sync.
- Make sure Braze access is allowed to the Redshift tables you want to sync. Braze will connect to Redshift over the internet.
- In your Redshift instance, set up the table(s) or view(s) you want to sync to Braze.
- Create a new integration in the Braze dashboard.
- Test the integration and start the sync.
- Create a service account and allow access to the BigQuery project(s) and dataset(s) that contain the data you want to sync.
- In your BigQuery account, set up the table(s) or view(s) you want to sync to Braze.
- Create a new integration in the Braze dashboard.
- Test the integration and start the sync.
- Create a service account and allow access to the Databricks project(s) and dataset(s) that contain the data you want to sync.
- In your Databricks account, set up the table(s) or view(s) you want to sync to Braze.
- Create a new integration in the Braze dashboard.
- Test the integration and start the sync.
There may be two to five minutes of warm-up time when Braze connects to Classic and Pro SQL instances, which will lead to delays during connection setup and testing, as well as at the beginning of scheduled syncs. Using a serverless SQL instance will minimize warmup time and improve query throughput, but may result in slightly higher integration costs.
Step 1: Set up tables or views
Step 1: Set up the table
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
CREATE DATABASE BRAZE_CLOUD_PRODUCTION;
CREATE SCHEMA BRAZE_CLOUD_PRODUCTION.INGESTION;
CREATE OR REPLACE TABLE BRAZE_CLOUD_PRODUCTION.INGESTION.USERS_ATTRIBUTES_SYNC (
UPDATED_AT TIMESTAMP_NTZ(9) NOT NULL DEFAULT SYSDATE(),
--at least one of external_id, alias_name and alias_label, email, phone, or braze_id is required
EXTERNAL_ID VARCHAR(16777216),
--if using user alias, both alias_name and alias_label are required
ALIAS_LABEL VARCHAR(16777216),
ALIAS_NAME VARCHAR(16777216),
--braze_id can only be used to update existing users created through the Braze SDK
BRAZE_ID VARCHAR(16777216),
--If you include both email and phone, we will use the email as the primary identifier
EMAIL VARCHAR(16777216),
PHONE VARCHAR(16777216),
PAYLOAD VARCHAR(16777216) NOT NULL
);
You can name the database, schema, and table as you’d like, but the column names should match the preceding definition.
UPDATED_AT- The time this row was updated in or added to the table. We will only sync rows that have been added or updated since the last sync.- User identifier columns - Your table may contain one or more user identifier columns. Each row should only contain one identifier (either
external_id, the combination ofalias_nameandalias_label, orbraze_id). A source table may have columns for one, two, or all three identifier types.EXTERNAL_ID- This identifies the user you want to update. This should match theexternal_idvalue used in Braze.ALIAS_NAMEandALIAS_LABEL- These two columns create a user alias object.alias_nameshould be a unique identifier, andalias_labelspecifies the type of alias. Users may have multiple aliases with different labels but only onealias_nameperalias_label.BRAZE_ID- The Braze user identifier. This is generated by the Braze SDK, and new users cannot be created using a Braze ID through Cloud Data Ingestion. To create new users, specify an external user ID or user alias.EMAIL- The user’s email address. If multiple profiles with the same email address exist, the most recently updated profile will be prioritized for updates. If you include both email and phone, we will use the email as the primary identifier.PHONE- The user’s email address. If multiple profiles with the same phone number exist, the most recently updated profile will be prioritized for updates.
PAYLOAD- This is a JSON string of the fields you want to sync to the user in Braze.
Step 2: Set up the role and database permissions
1
2
3
4
5
CREATE ROLE BRAZE_INGESTION_ROLE;
GRANT USAGE ON DATABASE BRAZE_CLOUD_PRODUCTION TO ROLE BRAZE_INGESTION_ROLE;
GRANT USAGE ON SCHEMA BRAZE_CLOUD_PRODUCTION.INGESTION TO ROLE BRAZE_INGESTION_ROLE;
GRANT SELECT ON TABLE BRAZE_CLOUD_PRODUCTION.INGESTION.USERS_ATTRIBUTES_SYNC TO ROLE BRAZE_INGESTION_ROLE;
Update the names as needed, but the permissions should match the preceding example.
Step 3: Set up the warehouse and give access to Braze role
1
2
3
CREATE WAREHOUSE BRAZE_INGESTION_WAREHOUSE;
GRANT USAGE ON WAREHOUSE BRAZE_INGESTION_WAREHOUSE TO ROLE BRAZE_INGESTION_ROLE;
The warehouse will need to have the auto-resume flag on. If not, you will need to grant Braze additional OPERATE privileges on the warehouse for us to turn it on when it’s time to run the query.
Step 4: Set up the user
1
2
3
CREATE USER BRAZE_INGESTION_USER;
GRANT ROLE BRAZE_INGESTION_ROLE TO USER BRAZE_INGESTION_USER;
After this step, you will share connection information with Braze and receive a public key to append to the user.
When connecting different workspaces to the same Snowflake account, you must create a unique user for each Braze workspace where you are creating an integration. Within a workspace, you can reuse the same user across integrations, but integration creation will fail if a user on the same Snowflake account is duplicated across workspaces.
Step 5: Allow Braze IPs in Snowflake network policy (optional)
Depending on the configuration of your Snowflake account, you may need to allow the following IP addresses in your Snowflake network policy. For more information on enabling this, see the relevant Snowflake documentation on modifying a network policy.
For Instances US-01, US-02, US-03, US-04, US-05, US-06, US-07 |
For Instances EU-01 and EU-02 |
|---|---|
23.21.118.191 |
52.58.142.242 |
34.206.23.173 |
52.29.193.121 |
50.16.249.9 |
35.158.29.228 |
52.4.160.214 |
18.157.135.97 |
54.87.8.34 |
3.123.166.46 |
54.156.35.251 |
3.64.27.36 |
52.54.89.238 |
3.65.88.25 |
18.205.178.15 |
3.68.144.188 |
3.70.107.88 |
Step 1: Set up the table
Optionally, set up a new Database and Schema to hold your source table
1
2
CREATE DATABASE BRAZE_CLOUD_PRODUCTION;
CREATE SCHEMA BRAZE_CLOUD_PRODUCTION.INGESTION;
Create a table (or view) to use for your CDI integration
1
2
3
4
5
6
7
8
9
10
11
12
13
14
CREATE TABLE BRAZE_CLOUD_PRODUCTION.INGESTION.USERS_ATTRIBUTES_SYNC (
updated_at timestamptz default sysdate,
--at least one of external_id, alias_name and alias_label, or braze_id is required
external_id varchar,
--if using user alias, both alias_name and alias_label are required
alias_label varchar,
alias_name varchar,
--braze_id can only be used to update existing users created through the Braze SDK
braze_id varchar,
--If you include both email and phone, we will use the email as the primary identifier
email varchar,
phone varchar,
payload varchar(max)
)
You can name the database, schema, and table as you’d like, but the column names should match the preceding definition.
UPDATED_AT- The time this row was updated in or added to the table. We will only sync rows that have been added or updated since the last sync.- User identifier columns. Your table may contain one or more user identifier columns. Each row should only contain one identifier (either
external_id, the combination ofalias_nameandalias_label, orbraze_id. A source table may have columns for one, two, or all three identifier types.EXTERNAL_ID- This identifies the user you want to update. This should match theexternal_idvalue used in Braze.ALIAS_NAMEandALIAS_LABEL- These two columns create a user alias object.alias_nameshould be a unique identifier, andalias_labelspecifies the type of alias. Users may have multiple aliases with different labels but only onealias_nameperalias_label.BRAZE_ID- The Braze user identifier. This is generated by the Braze SDK, and new users cannot be created using a Braze ID through Cloud Data Ingestion. To create new users, specify an external user ID or user alias.EMAIL- The user’s email address. If multiple profiles with the same email address exist, the most recently updated profile will be prioritized for updates. If you include both email and phone, we will use the email as the primary identifier.PHONE- The user’s email address. If multiple profiles with the same phone number exist, the most recently updated profile will be prioritized for updates.
PAYLOAD- This is a JSON string of the fields you want to sync to the user in Braze.
Step 2: Create user and grant permissions
1
2
3
CREATE USER braze_user PASSWORD '{password}';
GRANT USAGE ON SCHEMA BRAZE_CLOUD_PRODUCTION.INGESTION to braze_user;
GRANT SELECT ON TABLE USERS_ATTRIBUTES_SYNC TO braze_user;
These are the minimum required permissions for this user. If creating multiple CDI integrations, you may want to grant permissions to a schema or manage permissions using a group.
Step 3: Allow access to Braze IPs
If you have a firewall or other network policies, you must give Braze network access to your Redshift instance. Allow access from the below IPs corresponding to your Braze dashboard’s region.
You may also need to change your security groups to allow Braze to access your data in Redshift. Make sure to explicitly allow inbound traffic on the IPs below and on the port used to query your Redshift cluster (default is 5439). You should explicitly allow Redshift TCP connectivity on this port even if the inbound rules are set to “allow all”. In addition, it is important that the endpoint for the Redshift cluster be publicly accessible in order for Braze to connect to your cluster.
If you won’t want your Redshift cluster to be publicly accessible, you can set up a VPC and EC2 instance to use an ssh tunnel to access the Redshift data. Check out this AWS Knowledge Center post for more information.
For Instances US-01, US-02, US-03, US-04, US-05, US-06, US-07 |
For Instances EU-01 and EU-02 |
|---|---|
23.21.118.191 |
52.58.142.242 |
34.206.23.173 |
52.29.193.121 |
50.16.249.9 |
35.158.29.228 |
52.4.160.214 |
18.157.135.97 |
54.87.8.34 |
3.123.166.46 |
54.156.35.251 |
3.64.27.36 |
52.54.89.238 |
3.65.88.25 |
18.205.178.15 |
3.68.144.188 |
3.70.107.88 |
Step 1: Set up the table
Optionally, set up a new project or dataset to hold your source table.
1
CREATE SCHEMA BRAZE-CLOUD-PRODUCTION.INGESTION;
Create one or more tables to use for your CDI integration with the following fields:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
CREATE TABLE `BRAZE-CLOUD-PRODUCTION.INGESTION.USERS_ATTRIBUTES_SYNC`
(
updated_at TIMESTAMP DEFAULT current_timestamp,
--At least one of external_id, alias_name and alias_label, or braze_id is required
external_id STRING,
--If using user alias, both alias_name and alias_label are required
alias_name STRING,
alias_label STRING,
--braze_id can only be used to update existing users created through the Braze SDK
braze_id STRING,
--If you include both email and phone, we will use the email as the primary identifier
email STRING,
phone STRING,
payload JSON
);
| Field Name | Type | Mode |
|---|---|---|
UPDATED_AT |
TIMESTAMP | REQUIRED |
PAYLOAD |
JSON | REQUIRED |
EXTERNAL_ID |
STRING | NULLABLE |
ALIAS_NAME |
STRING | NULLABLE |
ALIAS_LABEL |
STRING | NULLABLE |
BRAZE_ID |
STRING | NULLABLE |
EMAIL |
STRING | NULLABLE |
PHONE |
STRING | NULLABLE |
You can name the project, dataset, and table as you’d like, but the column names should match the preceding definition.
UPDATED_AT- The time this row was updated in or added to the table. We will only sync rows that have been added or updated since the last sync.- User identifier columns. Your table may contain one or more user identifier columns. Each row should only contain one identifier (either
external_id, the combination ofalias_nameandalias_label, orbraze_id). A source table may have columns for one, two, or all three identifier types.EXTERNAL_ID- This identifies the user you want to update. This should match theexternal_idvalue used in Braze.ALIAS_NAMEandALIAS_LABEL- These two columns create a user alias object.alias_nameshould be a unique identifier, andalias_labelspecifies the type of alias. Users may have multiple aliases with different labels but only onealias_nameperalias_label.BRAZE_ID- The Braze user identifier. This is generated by the Braze SDK, and new users cannot be created using a Braze ID through Cloud Data Ingestion. To create new users, specify an external user ID or user alias.EMAIL- The user’s email address. If multiple profiles with the same email address exist, the most recently updated profile will be prioritized for updates. If you include both email and phone, we will use the email as the primary identifier.PHONE- The user’s email address. If multiple profiles with the same phone number exist, the most recently updated profile will be prioritized for updates. email varchar, phone_number varchar,
PAYLOAD- This is a JSON string of the fields you want to sync to the user in Braze.
Step 2: Create a Service Account and grant permissions
Create a service account in GCP for Braze to use to connect and read data from your table(s). The service account should have the below permissions:
- BigQuery Connection User: This will allow Braze to make connections
- BigQuery User: This will provide Braze access to run queries, read dataset metadata, and list tables.
- BigQuery Data Viewer: This will provide Braze access to view datasets and their contents.
- BigQuery Job User: This will provide Braze access to run jobs
After creating the service account and granting permissions, generate a JSON key. See more information on how to do this here. You will update this to the Braze dashboard later.
Step 3: Allow access to Braze IPs
If you have network policies in place, you must give Braze network access to your Big Query instance. Allow access from the below IPs corresponding to your Braze dashboard’s region.
For Instances US-01, US-02, US-03, US-04, US-05, US-06, US-07 |
For Instances EU-01 and EU-02 |
|---|---|
23.21.118.191 |
52.58.142.242 |
34.206.23.173 |
52.29.193.121 |
50.16.249.9 |
35.158.29.228 |
52.4.160.214 |
18.157.135.97 |
54.87.8.34 |
3.123.166.46 |
54.156.35.251 |
3.64.27.36 |
52.54.89.238 |
3.65.88.25 |
18.205.178.15 |
3.68.144.188 |
3.70.107.88 |
Step 1: Set up the table
Optionally, set up a new Catalog or Schema to hold your source table.
1
CREATE SCHEMA BRAZE-CLOUD-PRODUCTION.INGESTION;
Create one or more tables to use for your CDI integration with the following fields:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
CREATE TABLE `BRAZE-CLOUD-PRODUCTION.INGESTION.USERS_ATTRIBUTES_SYNC`
(
updated_at TIMESTAMP DEFAULT current_timestamp(),
--At least one of external_id, alias_name and alias_label, or braze_id is required
external_id STRING,
--If using user alias, both alias_name and alias_label are required
alias_name STRING,
alias_label STRING,
--braze_id can only be used to update existing users created through the Braze SDK
braze_id STRING,
--If you include both email and phone, we will use the email as the primary identifier
email STRING,
phone STRING,
payload STRING
);
| Field Name | Type | Mode |
|---|---|---|
UPDATED_AT |
TIMESTAMP | REQUIRED |
PAYLOAD |
STRING or STRUCT | REQUIRED |
EXTERNAL_ID |
STRING | NULLABLE |
ALIAS_NAME |
STRING | NULLABLE |
ALIAS_LABEL |
STRING | NULLABLE |
BRAZE_ID |
STRING | NULLABLE |
EMAIL |
STRING | NULLABLE |
PHONE |
STRING | NULLABLE |
You can name the schema and table as you’d like, but the column names should match the preceding definition.
UPDATED_AT- The time this row was updated in or added to the table. We will only sync rows that have been added or updated since the last sync.- User identifier columns. Your table may contain one or more user identifier columns. Each row should only contain one identifier (either
external_id, the combination ofalias_nameandalias_label, orbraze_id). A source table may have columns for one, two, or all three identifier types.EXTERNAL_ID- This identifies the user you want to update. This should match theexternal_idvalue used in Braze.ALIAS_NAMEandALIAS_LABEL- These two columns create a user alias object.alias_nameshould be a unique identifier, andalias_labelspecifies the type of alias. Users may have multiple aliases with different labels but only onealias_nameperalias_label.BRAZE_ID- The Braze user identifier. This is generated by the Braze SDK, and new users cannot be created using a Braze ID through Cloud Data Ingestion. To create new users, specify an external user ID or user alias.EMAIL- The user’s email address. If multiple profiles with the same email address exist, the most recently updated profile will be prioritized for updates. If you include both email and phone, we will use the email as the primary identifier.PHONE- The user’s email address. If multiple profiles with the same phone number exist, the most recently updated profile will be prioritized for updates.
PAYLOAD- This is a string or struct of the fields you want to sync to the user in Braze.
Step 2: Create a Access Token
In order for Braze to access Databricks, a personal access token needs to be created.
- In your Databricks workspace, select your Databricks username in the top bar, and then select User Settings from the drop-down.
- On the Access tokens tab, select Generate new token.
- Enter a comment that helps you to identify this token, such as “Braze CDI”, and change the token’s lifetime to no lifetime by leaving the Lifetime (days) box empty (blank).
- Select Generate.
- Copy the displayed token, and then select Done.
Keep the token in a safe place until you need to enter it on the Braze dashboard during the credential creation step.
Step 3: Allow access to Braze IPs
If you have network policies in place, you must give Braze network access to your Databricks instance. Allow access from the below IPs corresponding to your Braze dashboard’s region.
For Instances US-01, US-02, US-03, US-04, US-05, US-06, US-07 |
For Instances EU-01 and EU-02 |
|---|---|
23.21.118.191 |
52.58.142.242 |
34.206.23.173 |
52.29.193.121 |
50.16.249.9 |
35.158.29.228 |
52.4.160.214 |
18.157.135.97 |
54.87.8.34 |
3.123.166.46 |
54.156.35.251 |
3.64.27.36 |
52.54.89.238 |
3.65.88.25 |
18.205.178.15 |
3.68.144.188 |
3.70.107.88 |
Step 2: Create a new integration in the Braze dashboard
Go to Partner Integrations > Technology Partners. Find the Snowflake page and select Create new import sync.
If you are using the older navigation, go to Technology Partners.
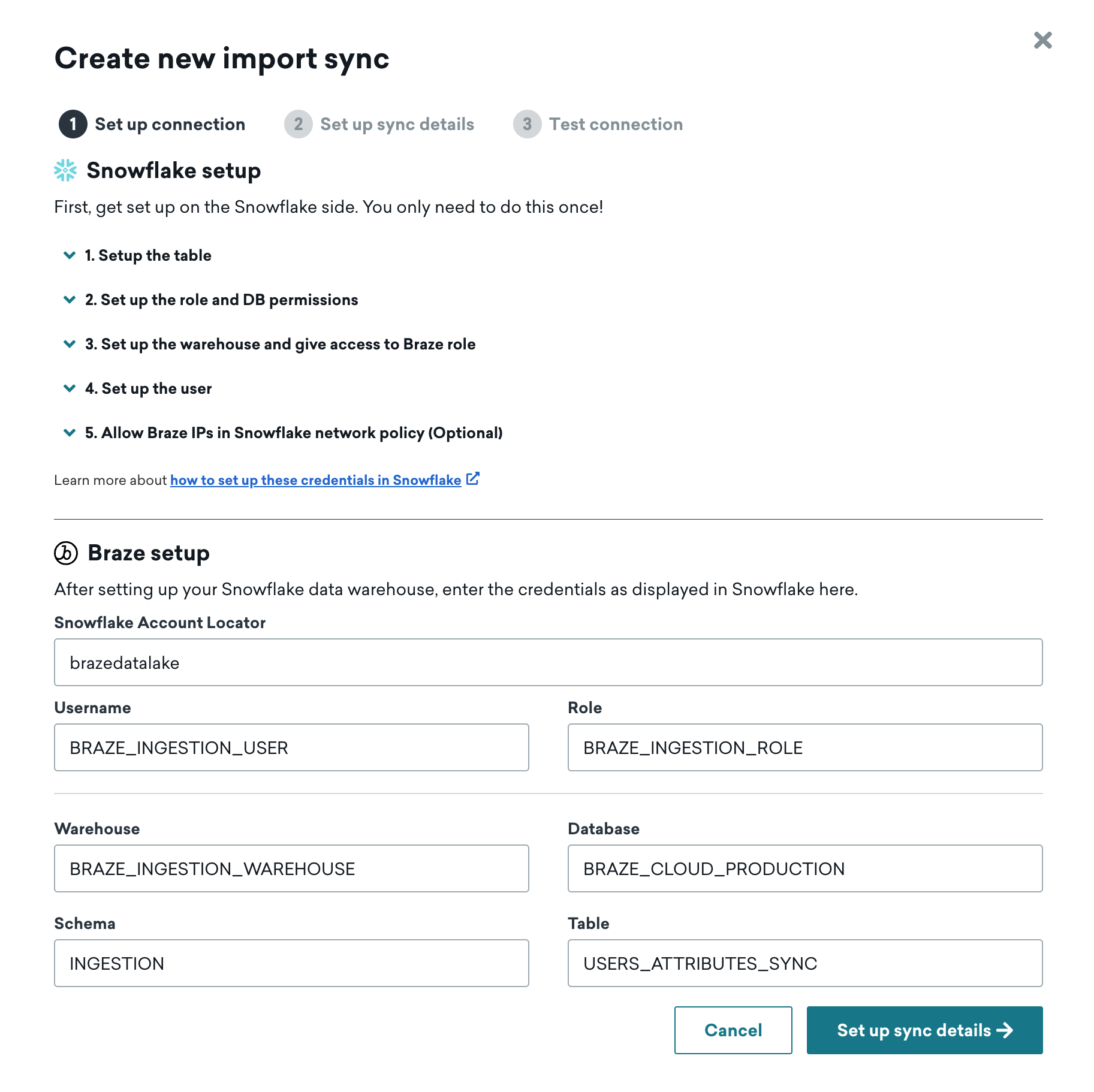
Step 1: Add Snowflake connection information and source table
Input the information for your Snowflake data warehouse and source table, then proceed to the next step.
Step 2: Configure sync details
Next, choose a name for your sync and input contact emails. We’ll use this contact information to notify you of any integration errors, such as unexpected removal of access to the table.
Contact emails will only receive notifications of global or sync-level errors such as missing tables, permissions, and others. They will not receive row-level issues. Global errors indicate critical problems with the connection that prevent syncs from running. Such problems can include the following:
- Connectivity issues
- Lack of resources
- Permissions issues
- (For catalogs syncs only) Catalog tier is out of space
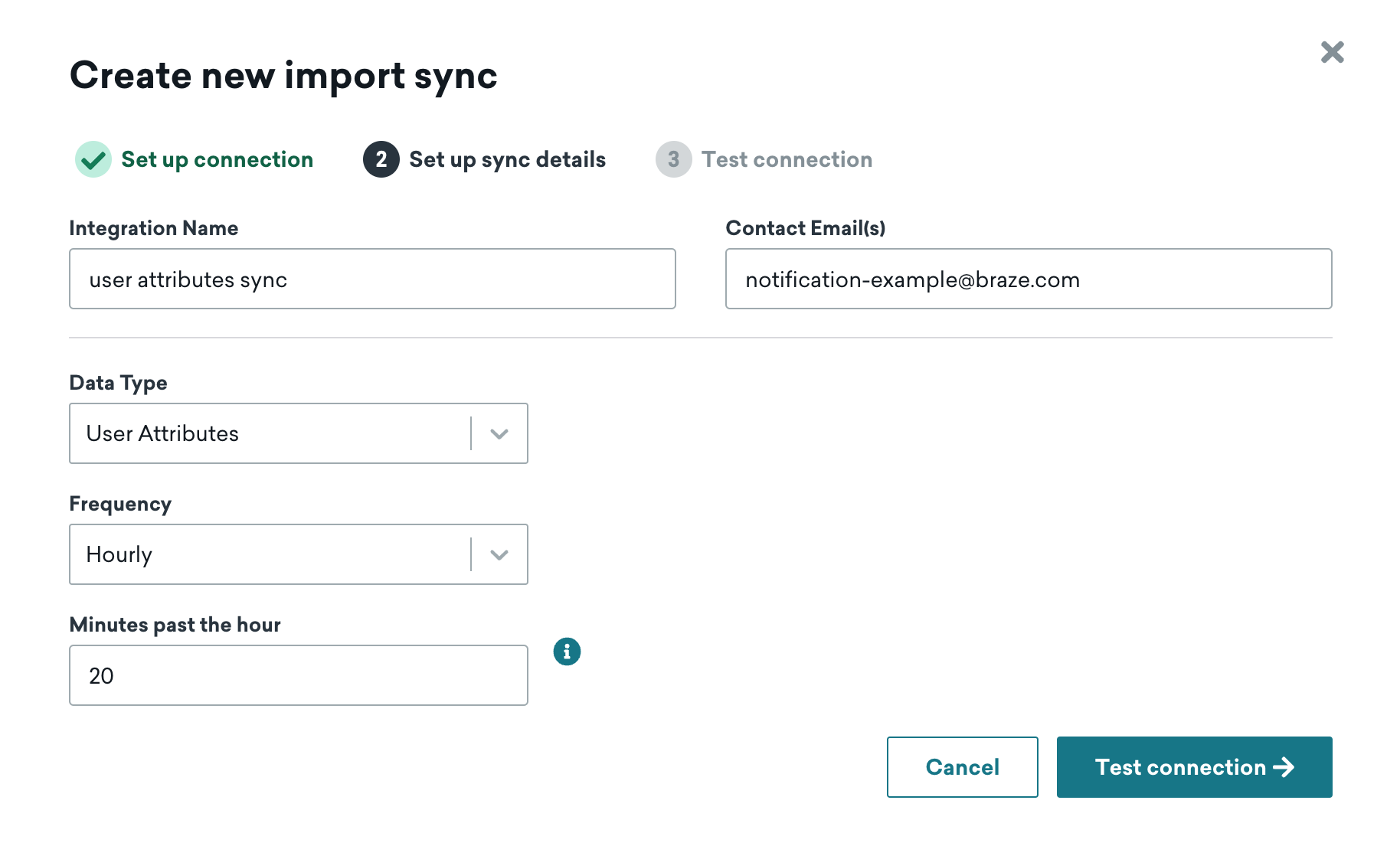
You will also choose the data type and sync frequency. Frequency can be anywhere from every 15 minutes to once per month. We’ll use the time zone configured in your Braze dashboard to schedule the recurring sync. Supported data types are Custom Attributes, Custom Events, and Purchase Events, and the data type for a sync cannot be changed after creation.
Add a public key to the Braze user
At this point, you must go back to Snowflake to complete the setup. Add the public key displayed on the dashboard to the user you created for Braze to connect to Snowflake.
For additional information on how to do this, see the Snowflake documentation. If you want to rotate the keys at any point, we can generate a new key pair and provide you with the new public key.
1
ALTER USER BRAZE_INGESTION_USER SET rsa_public_key='Braze12345...';
Go to Partner Integrations > Technology Partners. Find the Redshift page and select Create new import sync.
If you are using the older navigation, go to Technology Partners.
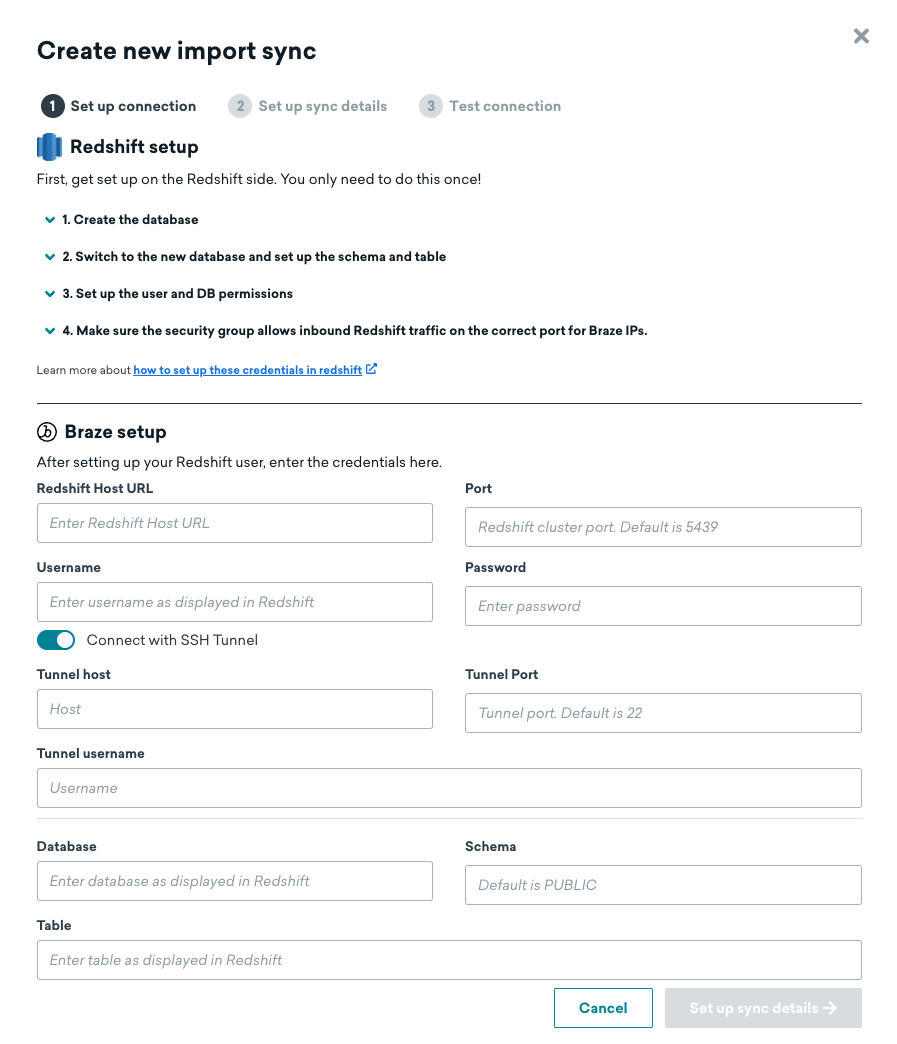
Step 1: Add Redshift connection information and source table
Input the information for your Redshift data warehouse and source table. If you are using a private network tunnel, toggle the slider and input the tunnel information. Then proceed to the next step.
Step 2: Configure sync details
Next, choose a name for your sync and input contact emails. We’ll use this contact information to notify you of any integration errors, such as unexpected removal of access to the table.
Contact emails will only receive notifications of global or sync-level errors such as missing tables, permissions, and others. They will not receive row-level issues. Global errors indicate critical problems with the connection that prevent syncs from running. Such problems can include the following:
- Connectivity issues
- Lack of resources
- Permissions issues
- (For catalogs syncs only) Catalog tier is out of space
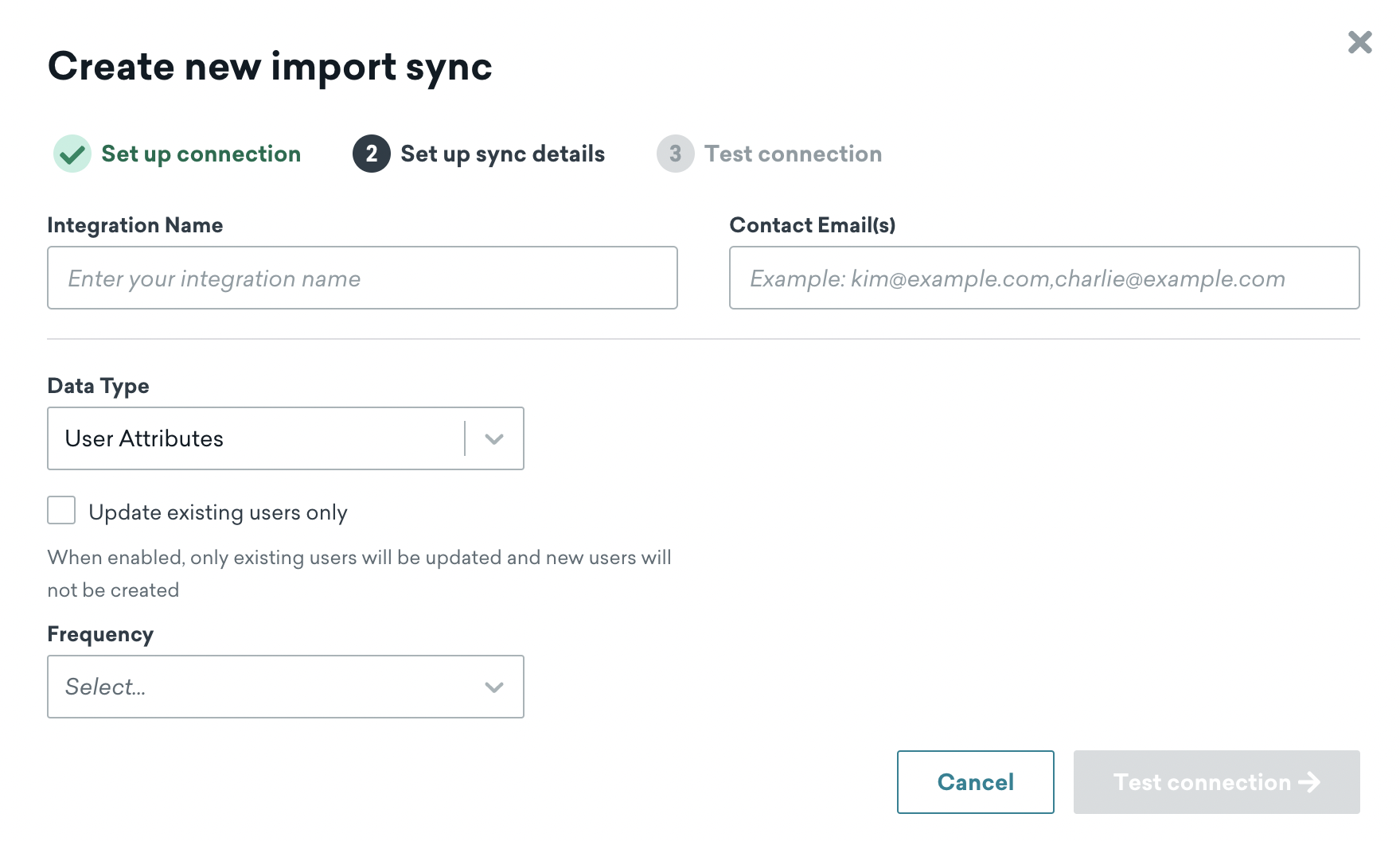
You will also choose the data type and sync frequency. Frequency can be anywhere from every 15 minutes to once per month. We’ll use the time zone configured in your Braze dashboard to schedule the recurring sync. Supported data types are Custom Attributes, Custom Events, and Purchase Events, and the data type for a sync cannot be changed after creation.
Go to Partner Integrations > Technology Partners. Find the BigQuery page and select Create new import sync.
If you are using the older navigation, go to Technology Partners.
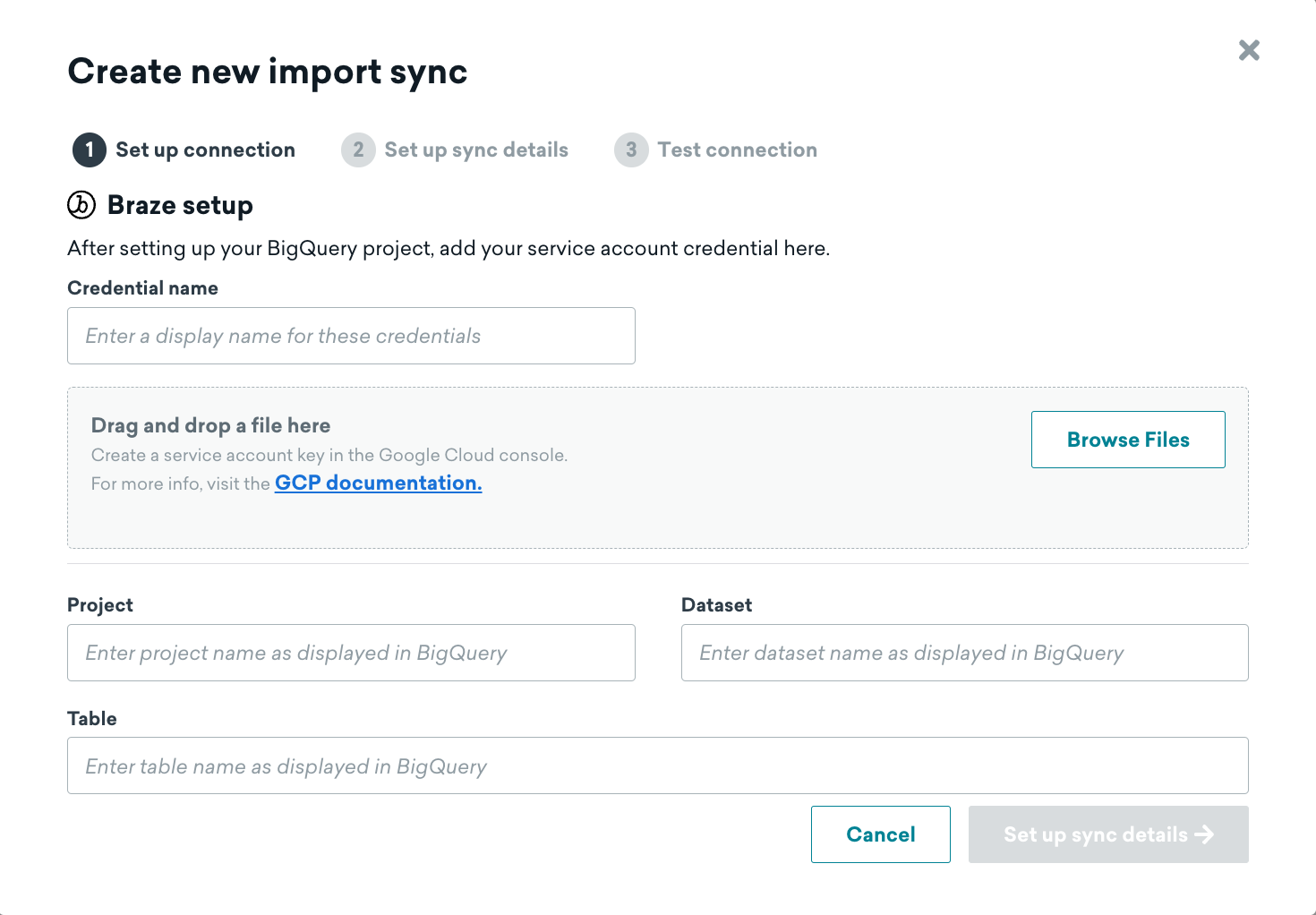
Step 1: Add BigQuery connection information and source table
Upload the JSON key and provide a name for the service account, then input the details of your source table.
Step 2: Configure sync details
Next, choose a name for your sync and input contact emails. We’ll use this contact information to notify you of any integration errors, such as unexpected removal of access to the table.
Contact emails will only receive notifications of global or sync-level errors such as missing tables, permissions, and others. They will not receive row-level issues. Global errors indicate critical problems with the connection that prevent syncs from running. Such problems can include the following:
- Connectivity issues
- Lack of resources
- Permissions issues
- (For catalogs syncs only) Catalog tier is out of space
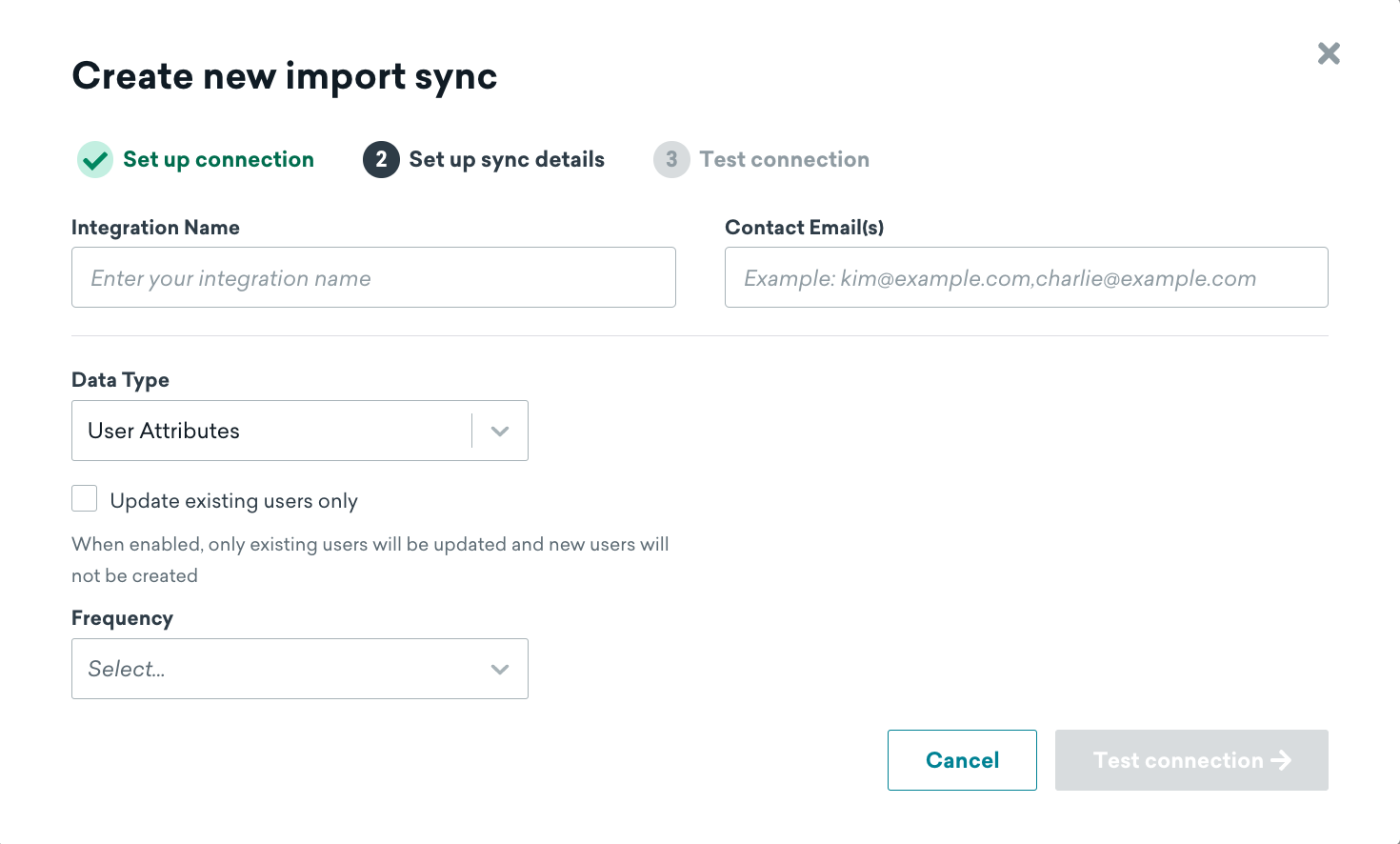
You will also choose the data type and sync frequency. Frequency can be anywhere from every 15 minutes to once per month. We’ll use the time zone configured in your Braze dashboard to schedule the recurring sync. Supported data types are Custom Attributes, Custom Events, Purchase Events, and User Deletes. The data type for a sync cannot be changed after creation.
Go to Partner Integrations > Technology Partners. Find the Databricks page and select Create new import sync.
If you are using the older navigation, go to Technology Partners.
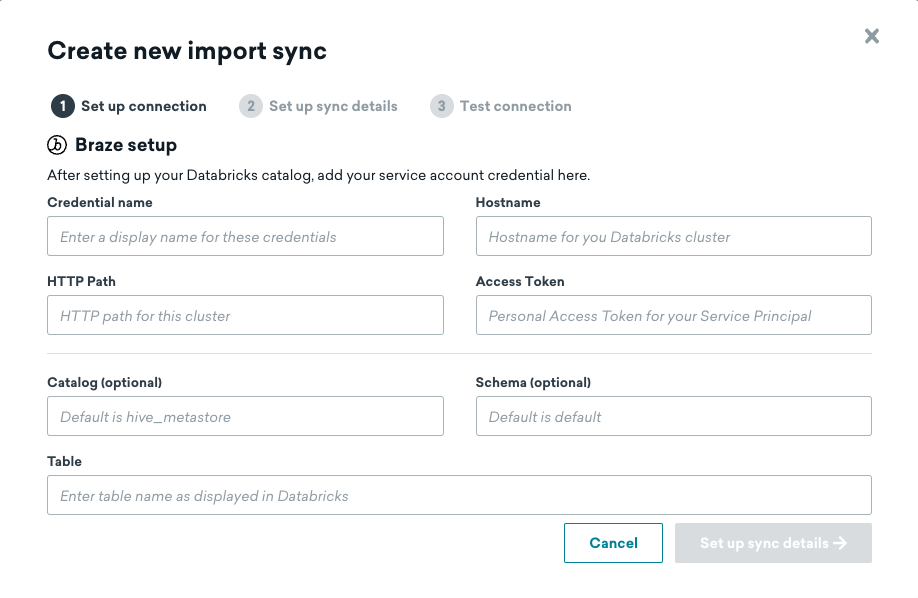
Step 1: Add Databricks connection information and source table
Input the information for your Databricks data warehouse and source table, then proceed to the next step.
Step 2: Configure sync details
Next, choose a name for your sync and input contact emails. We’ll use this contact information to notify you of any integration errors, such as unexpected removal of access to the table.
Contact emails will only receive notifications of global or sync-level errors such as missing tables, permissions, and others. They will not receive row-level issues. Global errors indicate critical problems with the connection that prevent syncs from running. Such problems can include the following:
- Connectivity issues
- Lack of resources
- Permissions issues
- (For catalogs syncs only) Catalog tier is out of space
You will also choose the data type and sync frequency. Frequency can be anywhere from every 15 minutes to once per month. We’ll use the time zone configured in your Braze dashboard to schedule the recurring sync. Supported data types are custom attributes, custom events, purchase events, and user deletes. The data type for a sync cannot be changed after creation.
Step 3: Test connection
Return to the Braze dashboard and select Test connection. If successful, you’ll see a preview of the data. If, for some reason, we can’t connect, we’ll display an error message to help you troubleshoot the issue.
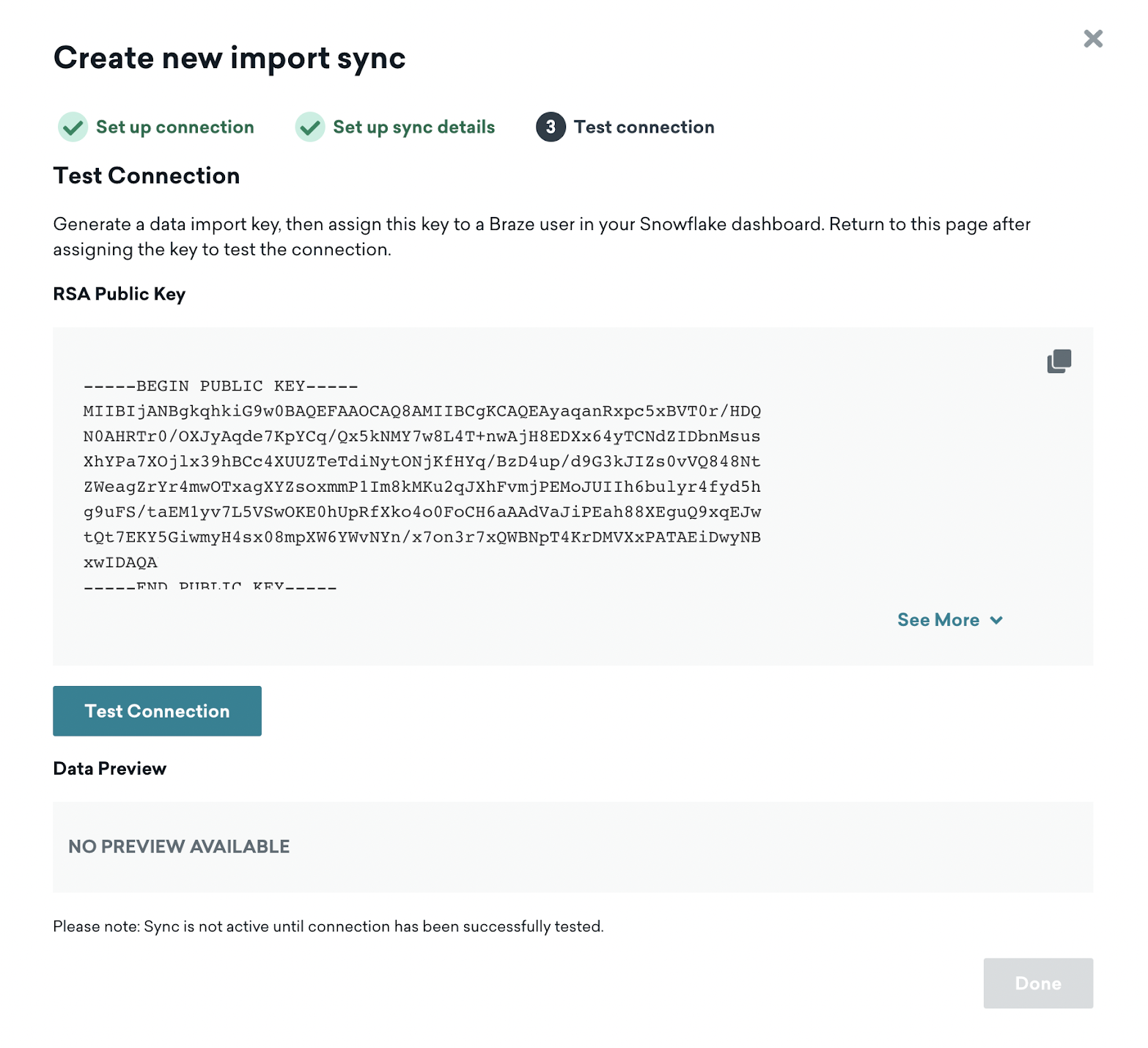
Return to the Braze dashboard and select Test connection. If successful, you’ll see a preview of the data. If, for some reason, we can’t connect, we’ll display an error message to help you troubleshoot the issue.
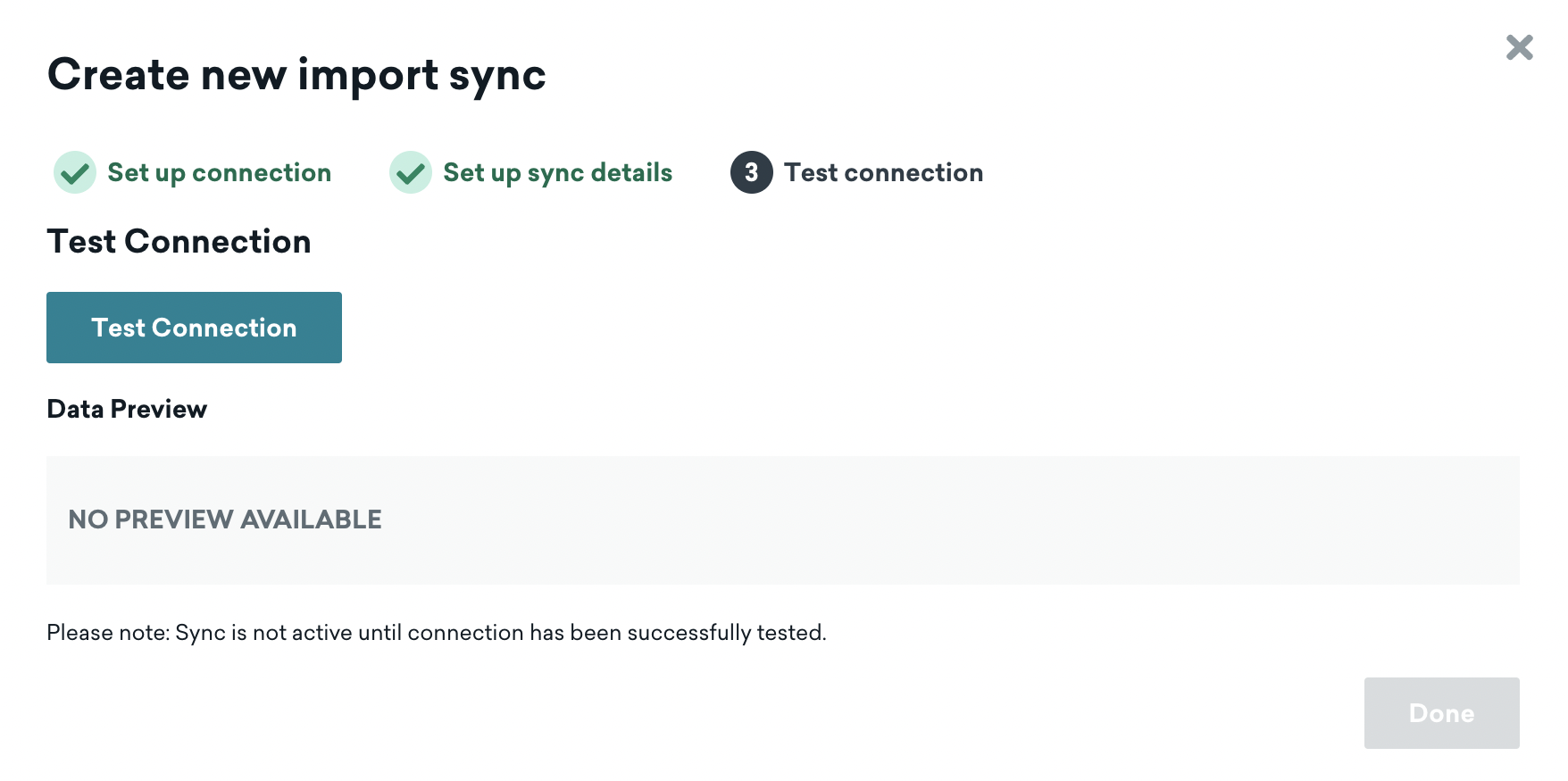
Return to the Braze dashboard and select Test connection. If successful, you’ll see a preview of the data. If, for some reason, we can’t connect, we’ll display an error message to help you troubleshoot the issue.

After all configuration details for your sync are entered, select Test connection. If successful, you’ll see a preview of the data. If, for some reason, we can’t connect, we’ll display an error message to help you troubleshoot the issue.
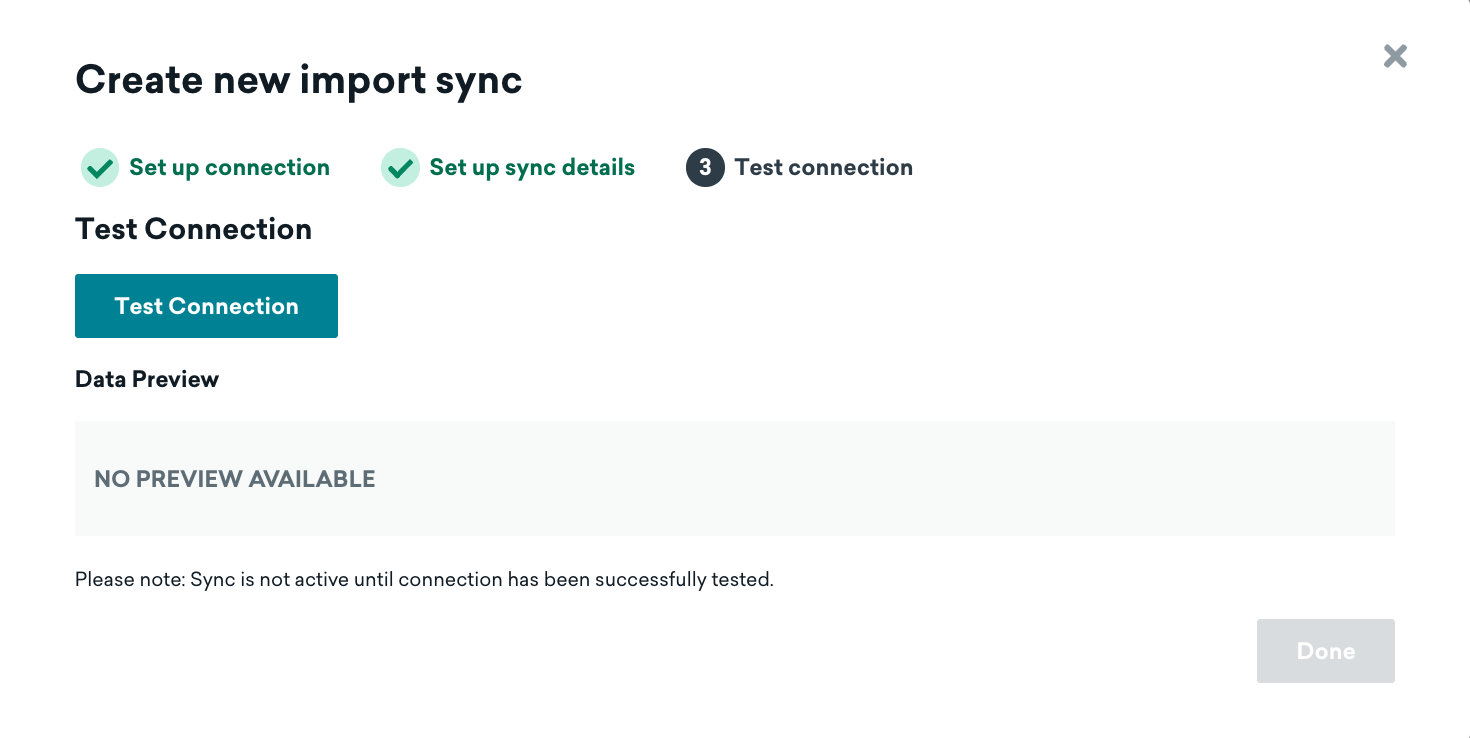
After all configuration details for your sync are entered, select Test connection. If successful, you’ll see a preview of the data. If, for some reason, we can’t connect, we’ll display an error message to help you troubleshoot the issue.
You must successfully test an integration before it can move from Draft to Active state. If you need to close out of the creation page, your integration will be saved, and you can revisit the details page to make changes and test.
Set up additional integrations or users (optional)
You may set up multiple integrations with Braze, but each integration should be configured to sync a different table. When creating additional syncs, you may reuse existing credentials if connecting to the Snowflake account.
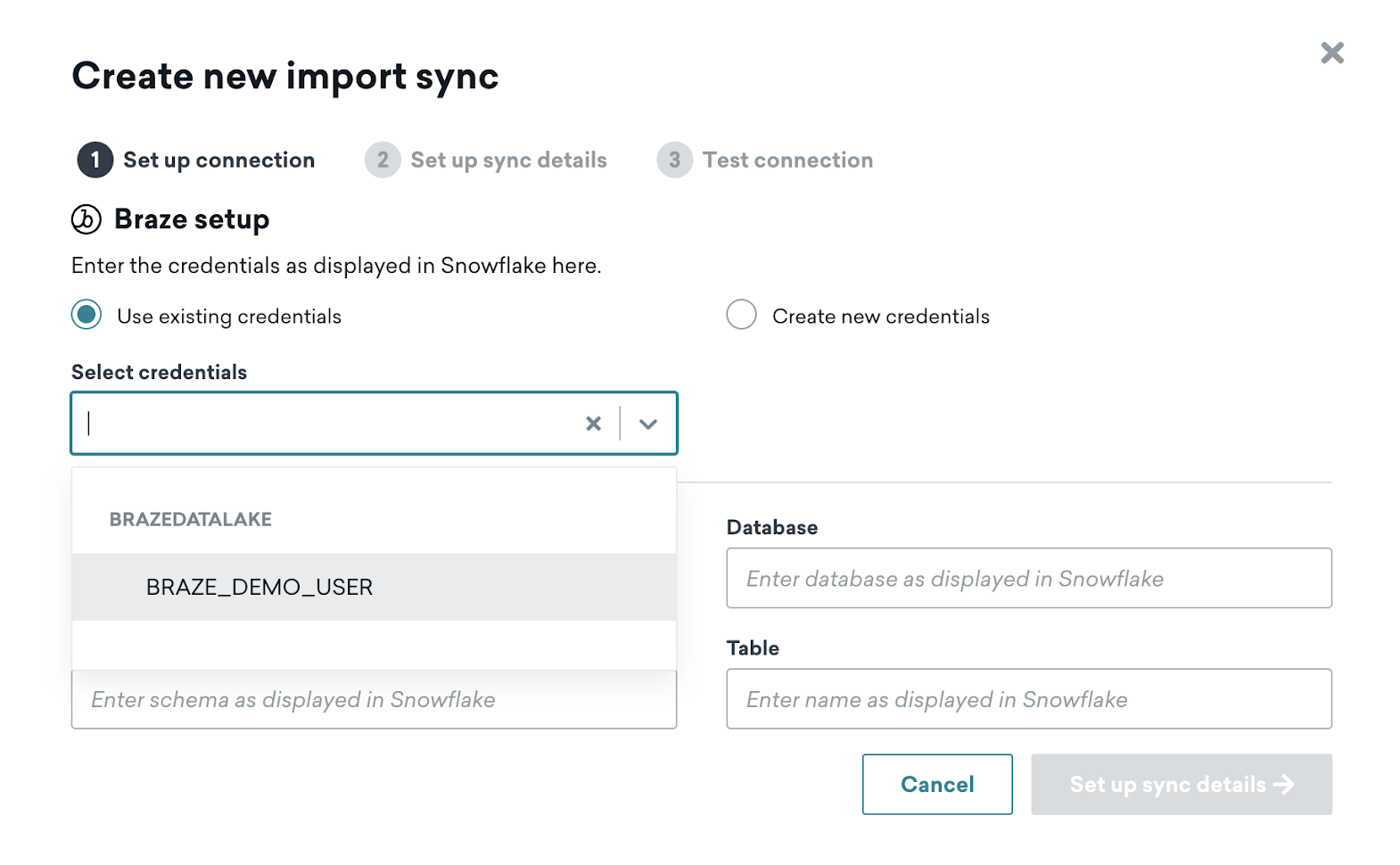
If you reuse the same user and role across integrations, you will not need to go through the step of adding the public key again.
You may set up multiple integrations with Braze, but each integration should be configured to sync a different table. When creating additional syncs, you may reuse existing credentials if connecting to the same Snowflake or Redshift account.
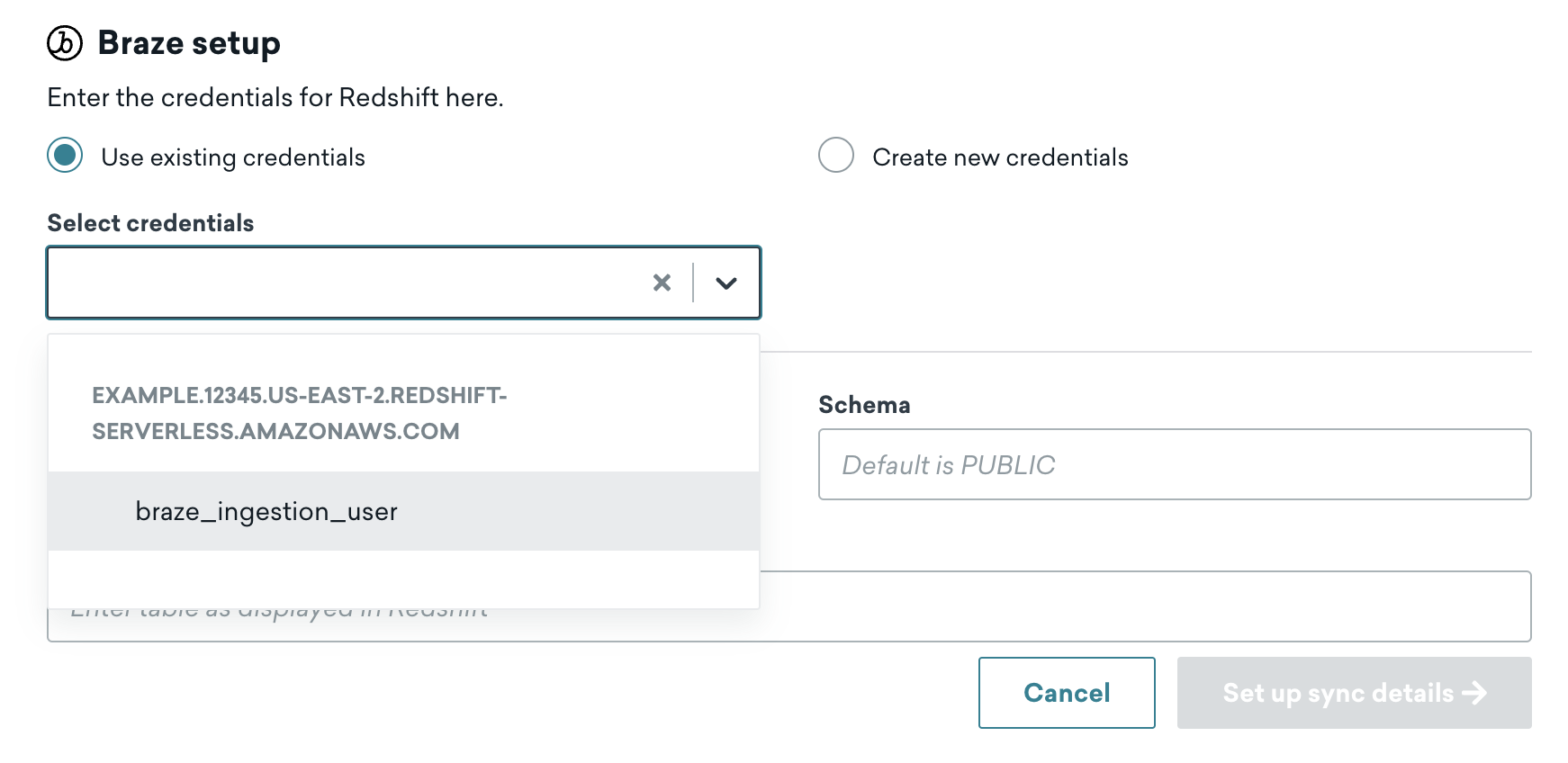
If you reuse the same user across integrations, you cannot delete the user in the Braze dashboard until it’s removed from all active syncs.
You may set up multiple integrations with Braze, but each integration should be configured to sync a different table. When creating additional syncs, you may reuse existing credentials if connecting to the same BigQuery account.
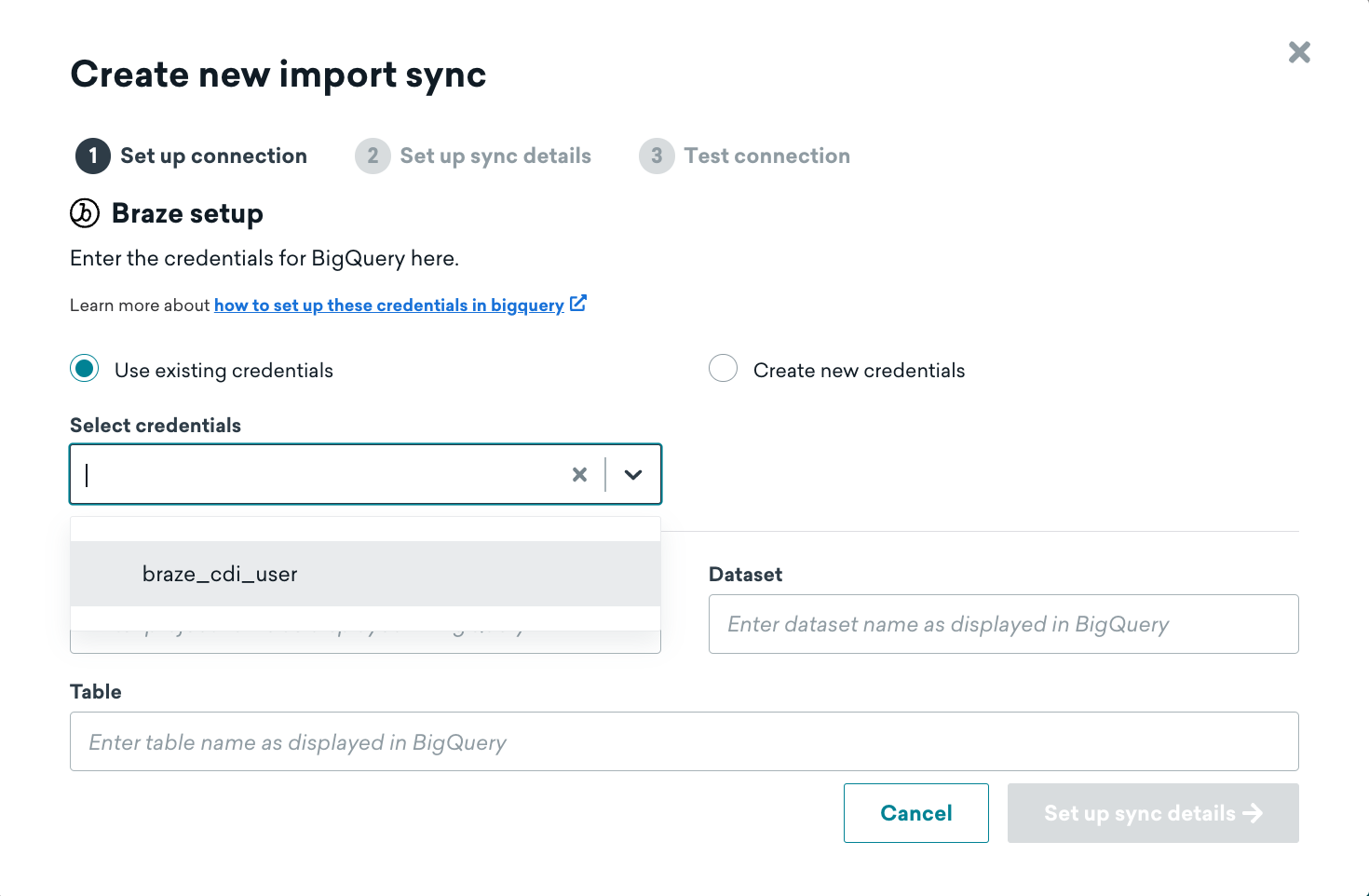
If you reuse the same user across integrations, you cannot delete the user in the Braze dashboard until it’s removed from all active syncs.
You may set up multiple integrations with Braze, but each integration should be configured to sync a different table. When creating additional syncs, you may reuse existing credentials if connecting to the same Databricks account.
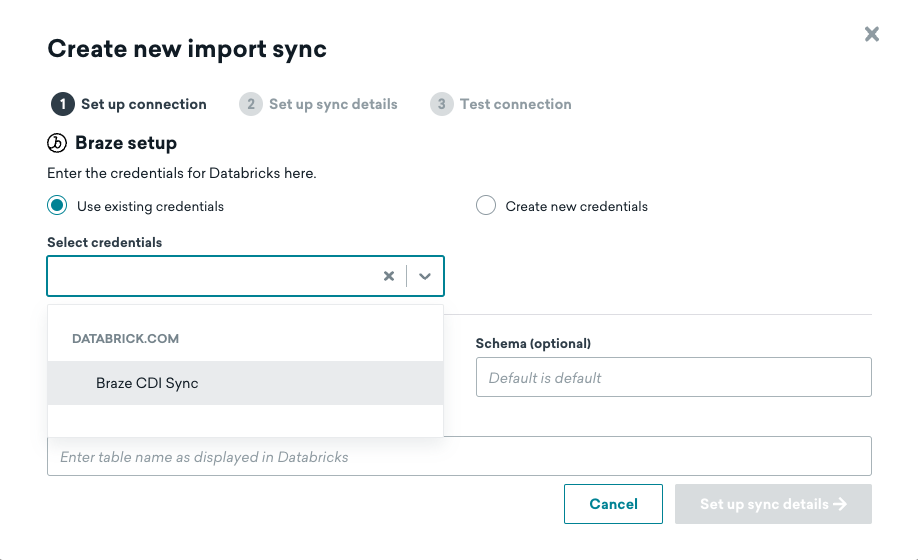
If you reuse the same user across integrations, you cannot delete the user in the Braze dashboard until it’s removed from all active syncs.
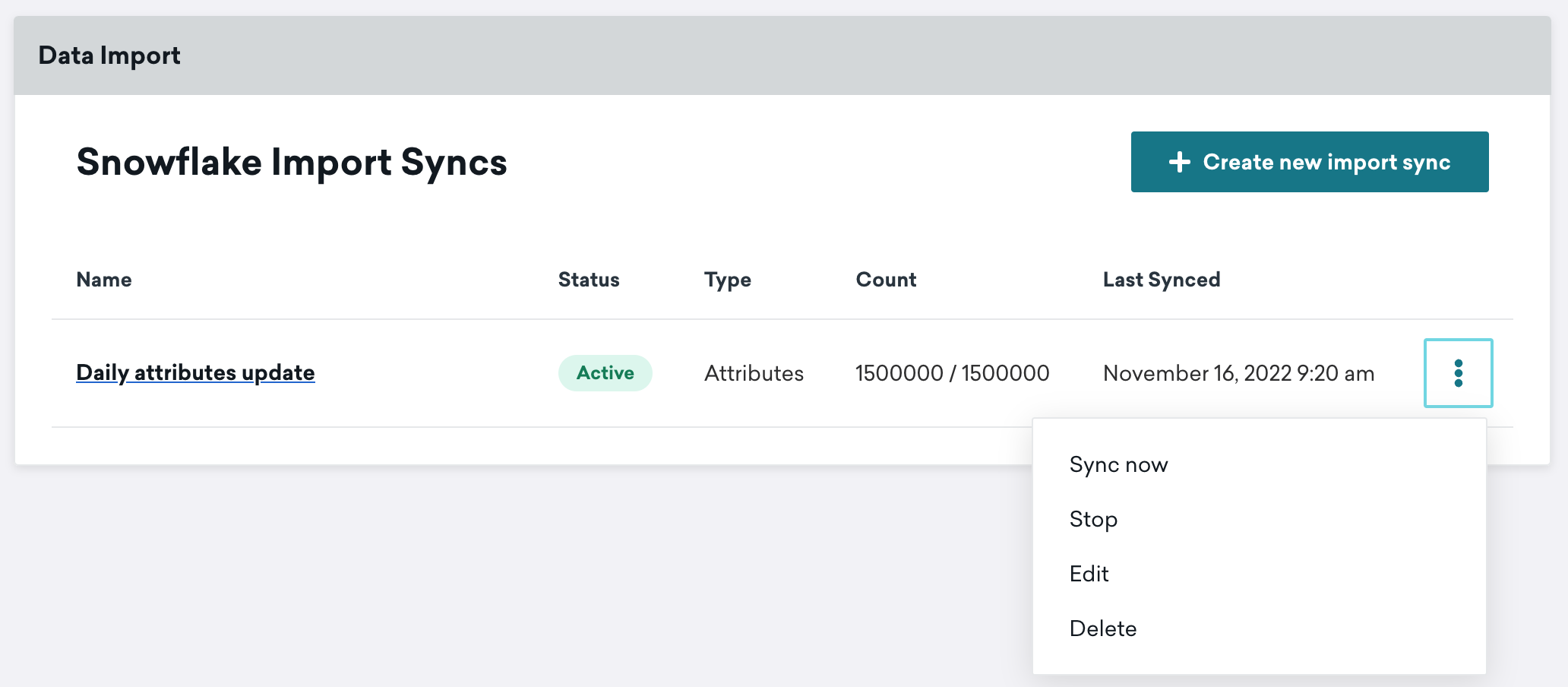
Running the sync
When activated, your sync will run on the schedule configured during setup. If you want to run the sync outside the normal testing schedule or to fetch the most recent data, select Sync Now. This run will not impact regularly scheduled future syncs.
When activated, your sync will run on the schedule configured during setup. If you want to run the sync outside the normal testing schedule or to fetch the most recent data, select Sync Now. This run will not impact regularly scheduled future syncs.
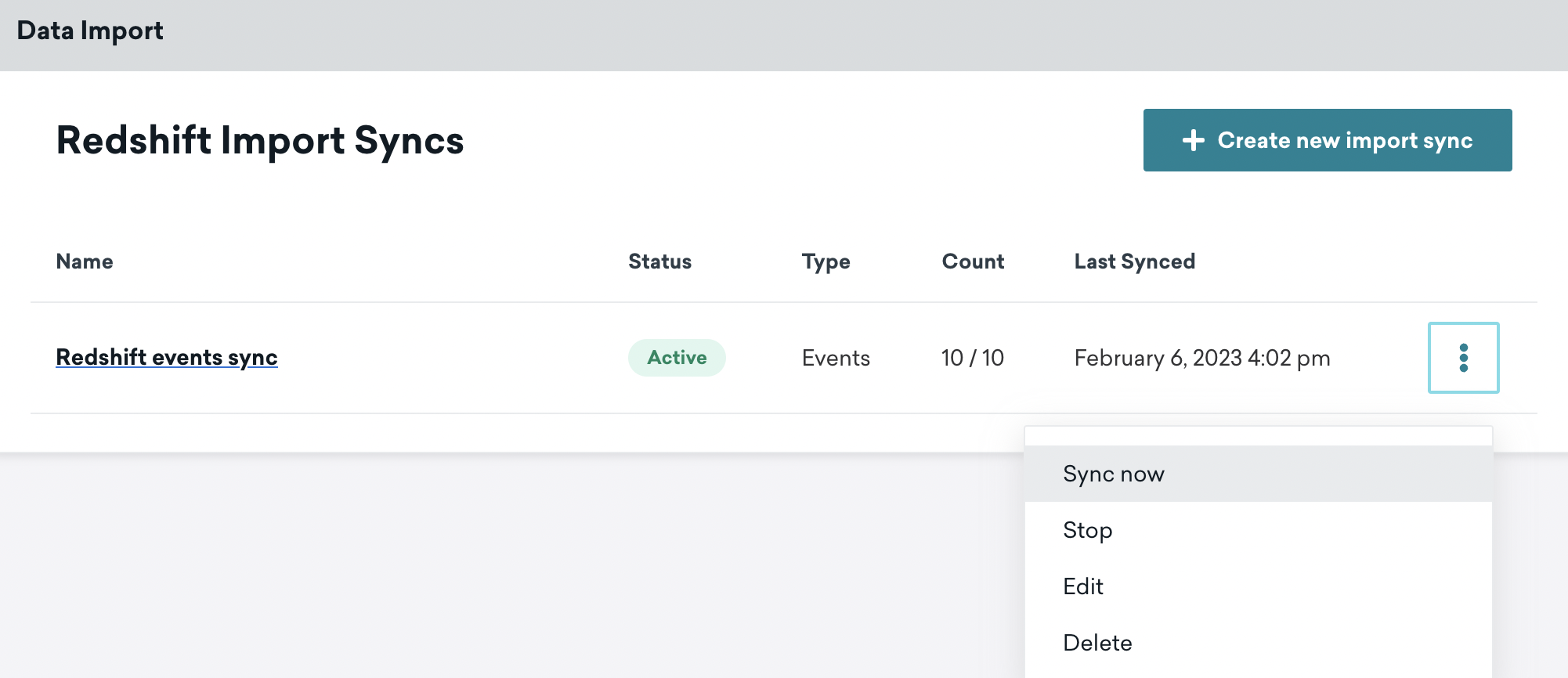
When activated, your sync will run on the schedule configured during setup. If you want to run the sync outside the normal testing schedule or to fetch the most recent data, select Sync Now. This run will not impact regularly scheduled future syncs.
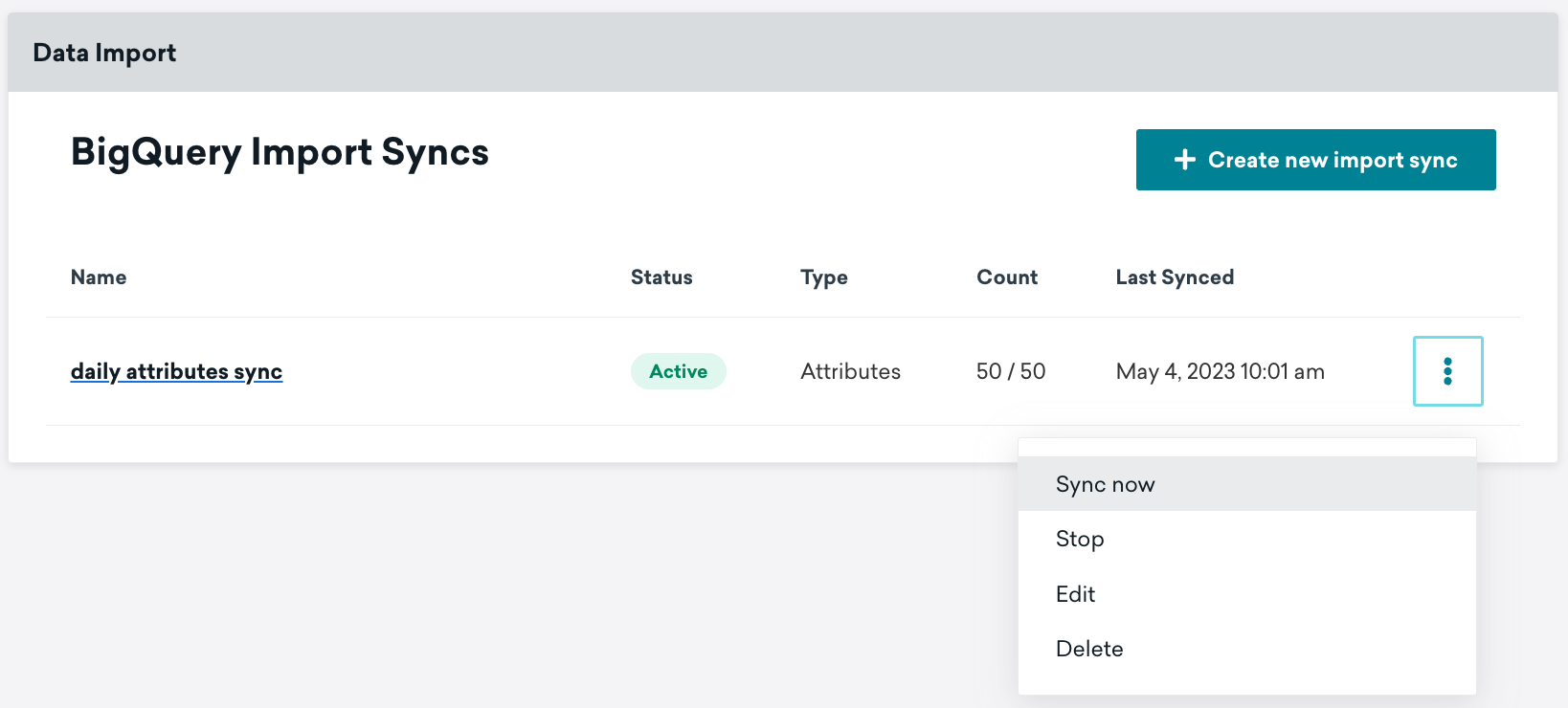
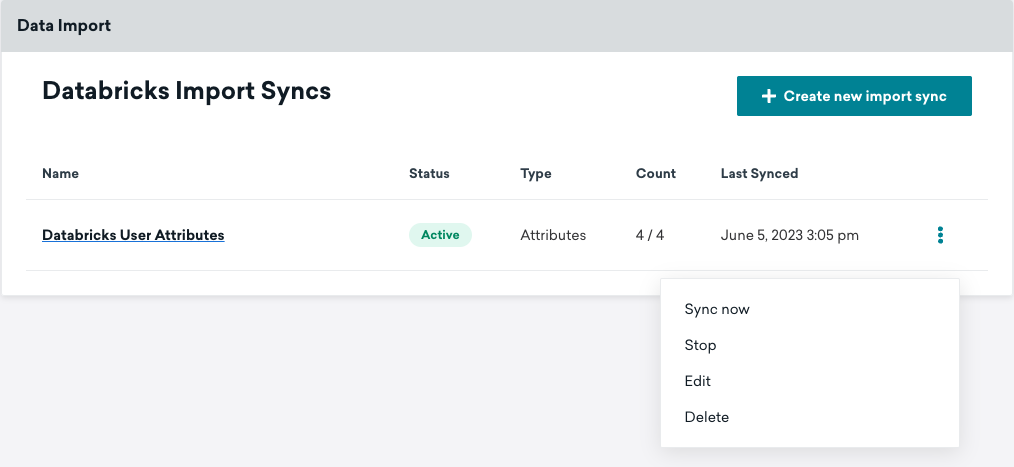
When activated, your sync will run on the schedule configured during setup. If you want to run the sync outside the normal testing schedule or to fetch the most recent data, select Sync Now. This run will not impact regularly scheduled future syncs.
 Edit this page on GitHub
Edit this page on GitHub