How Braze Overcame Infrastructure Challenges to Launch Content Cards at Scale
Published on February 24, 2023/Last edited on February 24, 2023/10 min read

Chris Haines
Senior Software Engineer, Platforms & Channels, BrazeFor most brands, the messaging channels they depend on to keep their customers engaged are out-of-product ones capable of reaching beyond the app or website to capture users’ attention—think email, SMS, or push notifications. But these channels can only support a subset of the use cases needed to drive strong long-term results; according to Braze research, US consumers who received a mix of out-of-product and in-product messages saw a 40% increase in sessions, a 25% rise in purchases, and 19% longer average user lifetimes.
To meet this need, Braze created a powerful new in-product channel—Content Cards—that was designed to support better customer engagement. But launching a whole new marketing channel is a challenging undertaking, especially given the scale that the Braze platform operates at. Read on to learn what challenges we faced in getting Content Cards out into the world and how our technical teams overcame them.
Braze first launched Content Cards as a channel back in the spring of 2019, shortly before I joined the Engineering department’s Platforms and Channels division. This new channel was developed to make it easier for brands to serve up personalized, persistent content seamlessly within their apps and website without interrupting the user experience. Content Cards are designed to support a range of implementations, allowing marketers to use them as an ongoing feed, an inbox for messages, or even carousels and other in-product experiences that feel like part of a native app or web experience.
Content Cards are extremely flexible by nature and can support a range of customizations—for instance, brands can control where and how Content Cards are rendered in their app/website, choose custom card expiration times, take advantage of API-based delivery of messages, and a lot more. That makes it a really powerful tool for reaching active users in ways that add value to their experience of your brand.
Given all that, it wasn’t shocking that Braze customers would flock to this new channel once it was released—but the scale of their usage and how quickly it ramped up surpassed our wildest expectations. One ironic aspect of the popularity of the channel was that it surfaced some infrastructure limitations that threatened to slow the growth of Content Cards over the long haul. To prevent that, we knew we needed solutions and we needed them fast.
Fortunately, our Engineering and DevOps teams were up to the challenge. Tackling this pressing issue required close collaboration, research, and a lot of teamwork—all while the clock was ticking away. Here’s the story of how we did it.
Content Cards: Building a New Messaging Channel
To understand some of the challenges we faced in connection with launching Content Cards, you have to understand what came before.
Back in 2013, Braze (then known as Appboy) launched its News Feed channel, allowing brands to include content feeds in their mobile apps. The channel was unique to our platform and gave marketers more options when it came to communicating with users inside their mobile apps; however, the channel had some limitations when it came to how it could be used and how brands could personalize the experiences they were serving up. In particular, it wasn’t compatible with our Connected Content dynamic content personalization feature, limiting brands’ ability to do real-time customization.
When Braze set out to build out Content Cards, one of the major goals was to replace the News Feed with a channel that was more flexible, modular, and capable of supporting advanced, in-the-moment personalization. To make that happen, the Platforms and Channels team made the call to build Content Cards by supplementing our existing storage with Postgres. These decisions were made to provide additional flexibility and stability to Content Cards, with the goal of providing brands with more control over the ways they leveraged this new channel, compared to what had been possible with the News Feed.
Confronting Scale Limitations
It was clear when we launched Content Cards that we’d achieved our goals—the new channel was much more powerful and flexible than News Feed, and was capable of supporting advanced, real-time personalization use cases. But as we noted above, the popularity of Content Cards forced us to confront some significant scaling and infrastructure-related issues that had the potential to undermine some of the benefits of the channel.
For starters, the high levels of usage meant that Content Cards began running into input/output (I/O) limitations in connection with Amazon Web Services (AWS) which is the cloud server provider the Braze platform is architected on. When we started seeing this issue, our team worked to increase the size of our instances, but found pretty quickly that it wasn’t enough to give us the bandwidth we needed. The result was that when usage got too high, servers would start to get overloaded, increasing how long it took for Content Card campaigns to send. And since this channel is designed to support real-time triggering and personalization, any delays could create potential issues.
Separately, we found ourselves running into scale-related issues with Postgres. As a result of the extremely high usage that Content Cards were seeing just after launch, we were pushing the database so hard that it wasn’t able to effectively clean up after itself. Under normal circumstances, Postgres runs a series of background maintenance processes—in particular, routine vacuuming—that help keep the system operating properly, especially when it comes to concurrency. However, because our usage was maxing out its resources on a consistent basis, Postgres’ Multi-Version Concurrency Control (MVCC) wasn’t able to do the periodic cleanup needed to avoid transaction ID exhaustion. If the issue wasn’t resolved, it could potentially cause the database to lock up, resulting in a subpar experience for the brands looking to leverage Content Cards.
Obviously, that was something we very much wanted to avoid.
All of the above happened right as I was joining Braze back in June 2019—and I soon found myself tasked with leading the response to these issues. But because I was so new to the team and wanted to ensure that I had the context and expert insight to address the problem effectively, I partnered with stakeholders across the Engineering and DevOps team.
Before we could make any meaningful changes, I knew we needed to get a deeper understanding of Postgres and what options were open to us to optimize queries. We started out by leveraging EXPLAIN and ANALYZE, which are commands you can use in Postgres that will show you more information about how queries will run, and then used that information to brainstorm ways to optimize our different indexes and reduce the burden on the relevant servers. And one early finding was that some of the work that had been done to try to reduce the burden we were seeing had actually made the issue worse.
With Content Cards, every message you send comes with an expiration date; that’s when the message will automatically go away and no longer be shown to the audience segment it was sent to. To try to keep our database to a manageable size, we’d been deleting expired Content Cards from the database, while also deleting Content Cards from campaigns that had been canceled by the team sending them.
In theory, that should have cut down on the size of the database, but, due to MVCC, storage space is not marked as free until the vacuum process completes, preventing those deletes from reducing the size of the database. In addition, each DELETE operation incremented the maximum transaction ID, accelerating the path towards transaction ID exhaustion.
Transitioning to a New Schema
Once we had a better picture of the problem, we all put our heads together to find a way to avoid hitting that maximum transaction ID limit. The process was exhilarating but also really challenging, in part because the initial solutions that we hit upon ended up not being workable. We were hoping to find an out-of-the-box tool that we could use to handle the problem, but there just wasn’t anything out there that would allow us to transition to a new schema without triggering significant downtime. In fact, when we looked into options, we found that the operation would take hours to complete with these outside approaches, since our database was multiple terabytes in size, making them a problematic fit for our needs.
However, the insights we gathered from that investigation ended up being instrumental in finding a way to solve the problem ourselves. During our work on this project, we built a different schema for Postgres that would allow us to do bulk deletions of expired Content Cards, making it possible to cut down on the size of the database without running into the issues we’d had before. We decided to use table partitioning to group Content Cards into cohorts by their expiration date. When the expiration date of a cohort passes, we are able to drop the entire table. This is a much more efficient process for Postgres than manually deleting rows and immediately freed up storage space. It also allowed for routine vacuuming to be performed, eliminating the threat of transaction ID exhaustion.
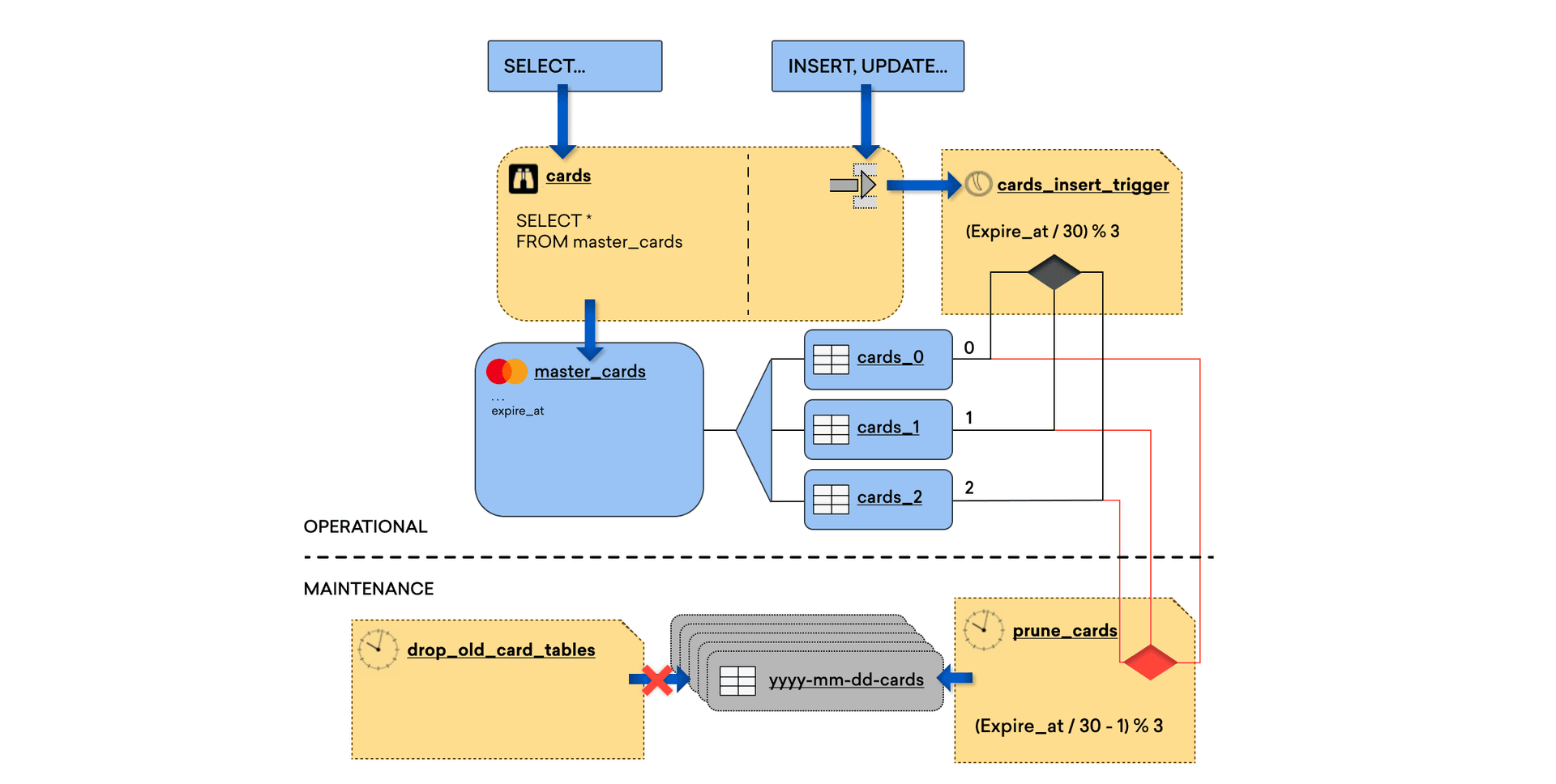
To make all of that possible, we had to find a way to migrate the information from our initial schema to the new one. Because the existing migration tools couldn’t do that successfully without triggering significant costs or downtime, I worked to develop a system that would make it possible for us to carry out a seamless migration.
One reason the downtime would be so significant with existing tools was that they required you to build an entire database in one go, so you had to wait a significant amount of time for the old and new schema to mirror each other. But because we had that expiration window, it allowed for us to build the new database progressively; that is, it was possible to update the new one while the old one was still functioning using parallel reads and writes.
In order to implement this, we built a configurable connection management system to determine which databases to write to, allowing for scheduling migration timetables. Then we integrated our in-house sharding system (which distributes data across multiple databases by hashing the user) into this system. This allowed us to horizontally scale our database infrastructure by adding additional Relational Database Service (RDS) clusters as we need them, giving us stability and flexibility at scale while addressing our AWS I/O limitations.
Final Thoughts
While it was definitely nerve-wracking at times to find myself dealing with infrastructure issues in a time-sensitive situation, we were able to implement our fix without triggering an incident and while maintaining 100% uptime. Plus, the work that we put in ended up having a significant positive impact for the companies that use Braze, allowing them to integrate Content Cards more easily into their campaigns and to do so without having to worry about scale.
To learn more about how Content Cards work and how they can support customer engagement, check out our user guide for in-depth information on card creation, customization, testing, and reporting.
Interested in working at Braze? We’re hiring for a variety of roles across our Engineering, Product Management, and User Experience teams. Check out our careers page to learn more about our open roles and our culture.
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.
Related Content
 Article8 min read
Article8 min readAI decision intelligence: How smart organizations are automating better marketing decisions
June 25, 2026 Article13 min read
Article13 min readAutonomous marketing: How AI agents are transforming campaigns from manual to self-driving
June 25, 2026 Article5 min read
Article5 min readRedefining retail in the age of AI
June 25, 2026