What’s Unbounded Data?
Published on August 31, 2018/Last edited on August 31, 2018/8 min read


Mary Kearl
WriterData is the lifeblood of modern marketing. Understanding your customers—their preferences and behaviors, the ways they prefer to engage with your brand—can be the difference between a successful marketing strategy and one that alienates your audience.
The rise of mobile has accelerated the collection of data from customers, but it’s also created new challenges when it comes to effectively managing and processing that data. To engage seriously in this new world, you need to be informed about new data concepts and the implications they have on customer engagement. Today, let’s take a look at one of those concepts—unbounded data.
What is unbounded data?
When we talk about unbounded data, we’re typically talking about two things: The first is the ever-evolving data sets that are generated by the constant stream of activity and behaviors from customers. The second is the ongoing processing of that data, which Google’s Tyler Akidau aptly refers to as unbounded data processing. The processing piece is the difference between sitting on piles of data, and taking action on data as it is generated.
Is there such a thing as “bounded data,” then?
100%, which is also how bounded data is characterized.
Because a bounded data set is a data set that’s finite by nature, there’s going to be a set amount of information in it. And because it’s finite, you have the completed whole of it at your disposal. If you’ve got a data set you collected two years ago sitting, unchanged, sitting in a spreadsheet or a data warehouse, that’s bounded data; it might well be accurate, but only as of the time it was exported. (If, for instance, it’s a list of people in your brand’s loyalty program as of April 5, 2016, it can tell you who was in your brand’s loyalty program on that date, but it’s not going to tell you who belongs to it now.)
Is customer engagement data bounded or unbounded data?
That depends how you look at it.
Because customer engagement data is usually based on information generated by the ongoing actions taken by millions of individuals as they open apps, visit websites, look at products, open (or don’t open) emails, among many, many other possible behaviors, the data set associated with those actions would logically be an unbounded one. So if we’re talking about a given user profile and the data that informs it, the constantly evolving nature of that information is going to reflect the unbounded nature of the data set.
That said, the information associated with a particular campaign may well be bounded. After all, once you send an email and the data comes in, you’re going to be looking at a complete, finite data set—people opened or didn’t, clicked or not, converted or failed to do so.
Wait, what’s batch processing (and what makes it different from data streaming)?
For a lot of people, batch processing IS data processing, because it’s the traditional way that data is processed and likely to be the kind of processing that they’re familiar with. Basically, batch processing works by bundling information into discrete units known as “windows.” These windows are processed on time-based schedules (for instance, every 24 hours) or when a given batch of data accumulated (e.g. this window is processed when it hits X amount of information), making it possible for information to flow between systems without constant human interaction but also ensuring the information that’s being shared is rarely being shared in the moment.
Data streaming works a little differently. Instead of processing data only when a specific time or threshold is hit, data streaming engines processes each unit of data individually, one after another after another—allowing for ongoing, in the moment processing of information across different systems. It’s the difference between a long-distance bus that waits for all the passengers to file on before leaving and a taxi stand where each car leaves based on the arrival of a new customer.
There’s also microbatching, which can be seen as falling between traditional batch processing and data streaming. With microbatching, where data is processed in a series of small, discreet batches, often at a frequent interval, potentially reducing latency.
What advantages does unbounded data processing have?
In the world of marketing, the difference between milliseconds and hours can make a massive difference when it comes to data processing. The value of the first-party data a given brand collects from their customers (such as web browsing or purchase/cart abandonment activity) is significant, but if you’re looking to take action based on that data, its value is highest the moment it collects and degrades over time—after all, the understanding it provides can be complicated by new behaviors or actions if you wait too long. By the same token, if you’re looking to dig deep into data to identify segments, trends, and other learnings that aren’t immediately obvious to the naked eye, having access to a larger, more current pool of relevant data can be the difference between discovering a key finding and analysis paralysis.
Can you talk about what bounded and unbounded data processing looks like at Braze?
Of course. The Braze customer engagement platform, which is involved in both data processing and actioning on that data, also allows brands to export data in traditional batches or using the Braze Currents data export feature. If your brand is using Braze, you can integrate the Braze SDK within your app or website and automatically begin collecting nuanced information about your customers and their engagement there, while also tracking how they respond to the messages you send across a range of different outreach channels (think email, push notifications, and more).
If you were looking to take that kind of information and send it to a data warehouse or analytics platform in the moment, Braze Currents makes that possible. By taking advantage of this feature, you can send that data directly into Amazon S3 or analytics platforms like Amplitude or Mixpanel, making it possible to perform the kinds of in-depth analysis that it takes to identify underlying trends or identify deeper insights associated with your target cohorts on a potentially unbounded data set.
On the other hand, if your brand is looking to get a snapshot of this data as it stands today, they might well make use of the Braze REST APIs to do it. This would necessarily be a bounded data set—because it’s complete as of the time it’s extracted—and taking this approach won’t give you an in the moment look at the information it contains. However, it does make it possible to do regular or ad hoc mass exports of this information.
In a case like this, determining which kind of data set is the one you need (and which data export tool you use) is going to depend on what your team is looking to accomplish.
So if I’m looking to take action on data in the moment, I’d need unbounded data processing then, right?
You need accurate, timely data—and leveraging an unbounded data set that’s updated in real time can provide that.
When it comes to sending messaging campaigns that leverage in the moment data, Braze, for instance, makes it possible using its Connected Content feature, which allows brands to dynamically pull in information from first- and third-party sources to enrich or customize their outreach. Because Connected Content works in a fundamentally ad hoc manner, grabbing information via API when affected messages are sent, this feature is most effective if the systems that the outreach is drawing on are being updated in real-time. After all, dynamically adjusting the push notifications you send to reflect the weather in each recipients’ region can make your messages feel more responsive and relevant—but not if you’re pulling that information from a public API that only has access to information about yesterday's weather.
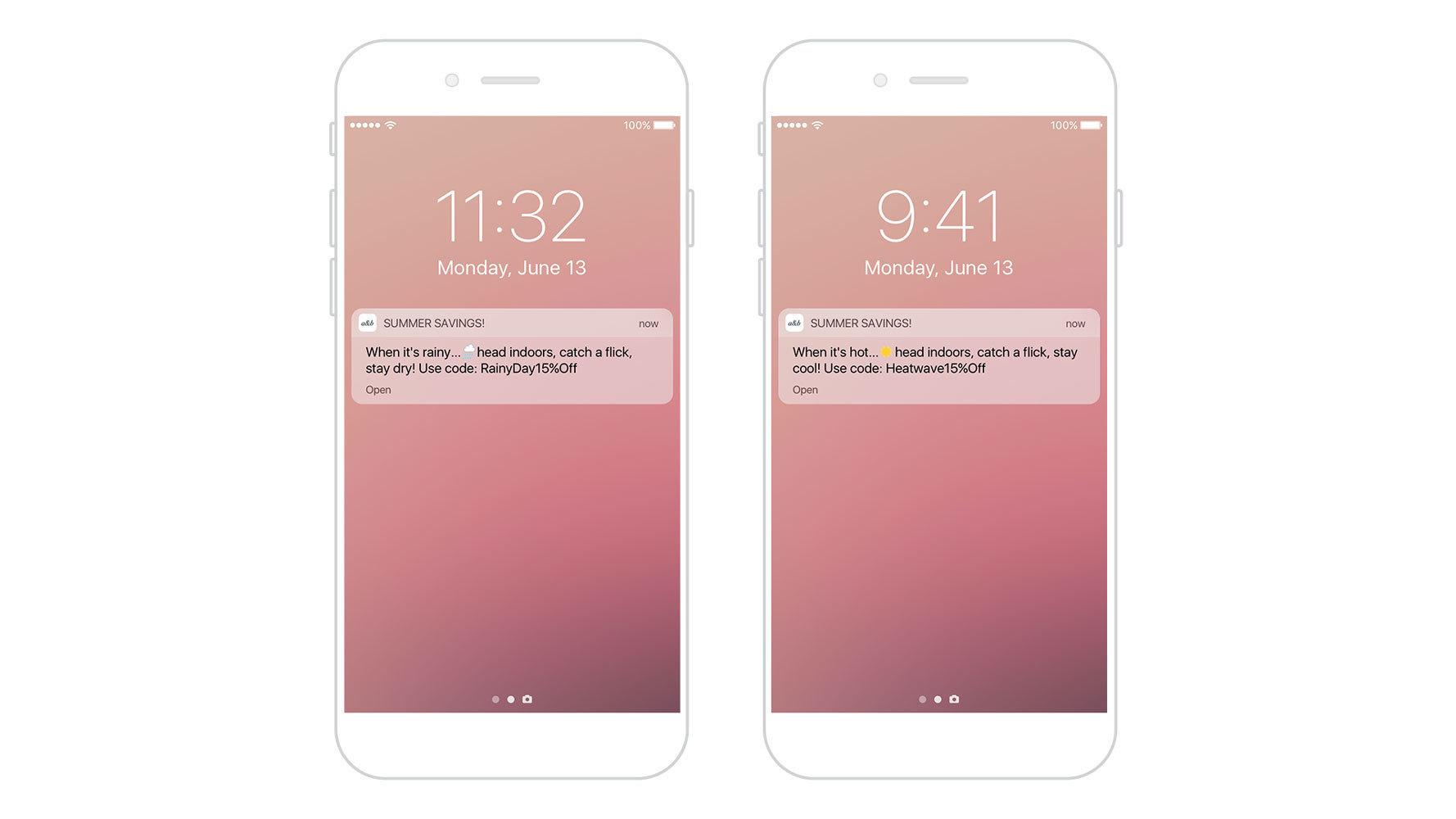
Is unbounded data the same as real-time data?
Yes and no. If your brand is leveraging a data streaming engine, it’s theoretically possible for you to be working from an unbounded data set that’s continually updating, supporting action on that data in the moment—which is what real-time data would seem to promise.
But the phrase “real-time data” has been degraded over the years, with many technology vendors and brands using it to refer to data processing that doesn’t happen in the moment. Often it means “kind-of, sort-of approaching real-time,” with data processing happening every few hours or every day (or even less often, in some cases). That lag doesn’t always matter; if you’re sending a messaging campaign for customers’ birthdays, the fact that “real-time” often doesn’t mean real-time isn’t likely to be an issue. But if the outreach you’re sending depends on relevancy, you want to be drawing from a data set that isn’t hours or days out of date.
Is all data more effective if it’s updated in real time?
Not necessarily. There are some customer profile attributes that are likely to remain more static (someone’s reported gender or home address, for example).
But while it’s true that not all types of data need to be processed in the moment to be useful, when all the data in your brand’s possession is batch processed, it can be hard to get a full picture of any individual customer at any given moment. After all, life doesn’t stop happening just because your data set is between batches; to really capture the consumer experience, brands need to move beyond approaches that place artificial restrictions on the unbounded, potentially infinite data sets that their customers generate.
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.


