Solve The Mysteries in Your Data
Published on October 12, 2021/Last edited on October 12, 2021/9 min read


Anna Mongillo
Business Intelligence Analyst at BrazeAt Braze, data is central to what we do. Helping brands achieve true data agility is important to us, and that’s a major reason we created Currents, our real-time, event-based data streaming product. With Currents, which provides granular information about user behavior down to the millisecond, brands can explore critical metrics like time to purchase, sessions per user, message frequency and cadence, monthly active users (MAU) per country, engagement metrics (clicks, impressions, etc.), and more.
At Braze, we know how valuable real-time data can be for your brand—but we also know how things can go awry, and how difficult it can be sometimes to diagnose technical issues. Parsing out nuances in a big dataset can feel like hunting for a needle in a haystack! That’s why, with Halloween upon us, we put together this series of “data whodunits” that might help your data team the next time they’re troubleshooting your Currents data. These cracked cases could serve as clues for solving a few mysteries of your own—or at the very least, they might equip your analytics team with a flashlight that will help illuminate the creepy, cobwebby corners of your data. For the night is dark, and full of terrors...

One day, our team was examining information related to user sessions and had an unexpected realization. We noticed that data from the session starts table went missing when joined to data from the first sessions table, like so:
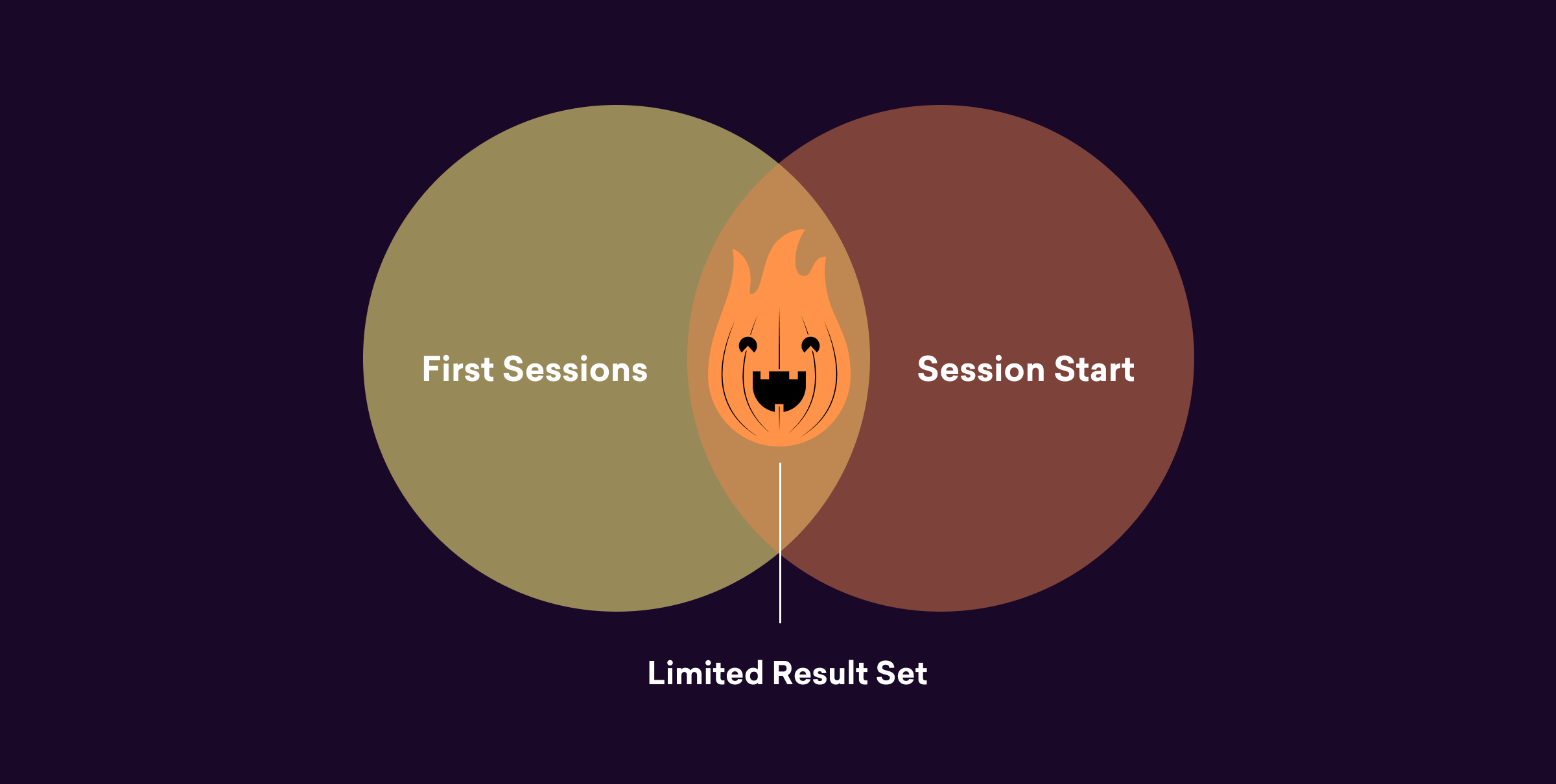
We’d been operating under the assumption that every app journey in the session starts table would have a corresponding first session—but, clearly this wasn’t always the case. After some research, we determined the root cause of this phenomenon: Something called “orphaned users.”
What is an orphaned user? Well, when an anonymous user (that is, a user without an external ID) is identified by a brand and the identified user in question already exists within Braze, the anonymous user is merged into the known user and then "orphaned." When this happens, some data is moved from the orphaned user profile to the identified user profile. During that process, the orphaned data is removed from the first sessions table, but all the activity attributed to that user in the past remains in other tables (read: The session starts table) with the original user id.
A standard user orphaning process merges all users in the app group that have a shared email address. The user to keep and the user(s) to merge are automatically determined with the following logic:
- The user that is kept in the first sessions table will be the identified user with the most recent session; all other users in the set will be merged into that user.
- If no identified users in the set have any sessions, then the identified user that was most recently updated—via API, for example—will be kept.
- If there are no identified users in the set, then the anonymous user with the most recent session will be the user to keep (and again, if no users in the set have a session, the kept user will be the anonymous user that was most recently updated).
- By default, the migration does not merge identified users. However, this setting can be overridden so that identified users can be merged if your team so desires.
Because we were performing an exclusive inner join with user_id in the join criteria, the orphaned users that were deleted from the first sessions table were causing a discrepancy between session start counts in the platform and session start counts in our Currents query. Mystery solved!
What should you do with this information? Fortunately, our analysis determined that this phenomenon is not very common; only around 1% of all users have been orphaned. However, do take note that this phenomenon may explain some differences between the session counts in the Braze dashboard and those in Currents when joining sessions to corresponding first sessions. If you have a particularly problematic percentage of sessions missing, ensure that there are no technical missteps in the way your team is identifying users—for instance, using email address as the external id for some users and not for others.

This time around, our data team noticed that the raw session end counts we were pulling in Currents were undercounted for an app group when compared to session start counts in the Braze dashboard. Logically, any given session start should have a corresponding session end, right? Well, once again we discovered that that’s not always true—at least, it’s not always true right away. This is because session end events that occur due to non-usage of the app, and they generally get flushed to the server at the time of the next session start.
What could this mean? Essentially, the Braze SDK caches data (e.g. sessions, custom events) and uploads that data periodically. Only after the data in question has been uploaded will the values be updated on the dashboard. The upload interval takes into account the state of the device and is governed by the quality of the network connection:

If there is no network connection, the data is cached locally on the device until the network connection is re-established. When the connection is re-established or the app is reopened, the data will be uploaded to Braze.
Need an example? Let's say you are a user. You open the app, it triggers a session start, and it flushes. Then you close the app, turn off your phone, or go out of service—now you're due a session end event (you ended your session) but there's nothing to log that (the app is not running/the device is off/the device has no network access) until you open the app and start your next session. Finally, you reopen the app—hours or days later—and the session end event for the previous session will finally be logged, backdated with the correct timestamp from when the session actually ended.
It’s also worth noting that the timeliness of session end data can be controlled by individual brands. Braze customers should ensure that there is a requestImmediateDataFlush invocation in the SDK integration directly after the session open, in order to prevent delayed collection for anybody who opens a session and immediately force-quits the app, turns off the device, or goes offline without waiting for that session start event to flush at the end of the standard 10-second flush interval. This approach will prevent session ends from being logged late or never logged at all, reducing the impact and frequency of this issue.
Our analyses suggest that in sum, nearly 99% (98.72%) of sessions are counted in the session end table across all app groups. The remaining 1-2% seems to be shouldered by brands that do not implement immediate data flushing in their SDK integration.
How does this affect you? Your data team may want to use the session end table to measure session activity instead of the session start table so that they can evaluate average session duration, which is particularly pertinent for brands in industries where session length is a KPI (streaming services, for example). However, depending on the app group being analyzed, this nuance may cause a discrepancy between the session data shown in the Braze dashboard and your own analyses.
If your data team is using the session ends table in Currents to pull session data (for instance, weekly active users, daily sessions per user, session volumes by country, etc.), you can do a sanity check with the Braze dashboard to ensure that your brand does not face large discrepancies between session start and end data. If your brand does have this issue, please use your session start Currents tables to pull the data in question and notify the team that session ends may not be getting counted properly, as this may cause metrics like session duration to be unreliable. Consider implementing a requestImmediateDataFlush invocation in the SDK integration directly after a given session open to mitigate this issue.

Finally, we’ve reached our last whodunit: Phantom purchases.
What is a phantom purchase? This refers to situations where purchases are not attributed to any app (the app ID field is null in the purchases table in Currents). This is because app_id is optional in the purchases object via the REST API. Brands can backfill or log purchase information however they want, including currency data. Therefore, much of the purchase activity information available is dependent on what your brand provides. If your team does not include app IDs with your users’ purchase information, it may be difficult to effectively analyze your data. For instance, if you want to look at time to purchase using Currents, it will be impossible to join your purchase data to your first session data using app ID in the join criteria.
How do you know if phantom purchases are affecting your brand and the analyses your data team is fulfilling? Investigate (or ask your analytics department to determine) what percentage of your purchase events in Currents are not attributed to any app ID. Our estimates suggest that this issue affects a decent number of purchase events in Currents, so don’t assume that your company is immune without checking. Because they are not attributed to any app which we service at Braze, these purchase events could be referring to anything—in-person purchases, fake purchases, backfilled data, and more. Keep this in mind when your data team is running analyses on your Currents data; after all, metrics like time to purchase or likelihood to buy may be more of a proxy if your team isn’t providing Braze the information needed to get a full picture.
Final Thoughts
Using Currents to get more granular with your data can be a major help when it comes to supporting your brand’s short- and long-term marketing strategy. But while advanced analytics capacity is always something to strive for, it’s all for naught if you can’t understand the nuances in the data you’re given. It’s important that you invest the time in understanding your data so that no monsters pop up to scare you.
Interested in learning more about Currents and how it can help support your customer engagement program? Check out our exclusive overview for a deeper dive into all things Currents.
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.