Cache Concurrency Control
Published on May 30, 2019/Last edited on May 30, 2019/6 min read


Jon Hyman
CTO, BrazeGetting Paged
It started like many operational stories do, with an Apdex page against one of our SDK API clusters at 2:22 a.m. Eastern Time, waking up one of Braze’s on-call engineers. Apdex for our APIs is a measure of the response time between when the API call is made and when our system returns. And in addition to the Apdex, one of our SDK API clusters was returning HTTP 503 Service Unavailable errors.
Apdex issues tend to mean that there is database slowness or heavy load on something that is causing the delays. Sure enough, looking at one of our API clusters in DataDog we saw high CPU utilization on one of our clusters for API servers dedicated to one of our customers. On this graph, each honeycomb cell represents an API server, and the more orange it is, the higher the CPU.
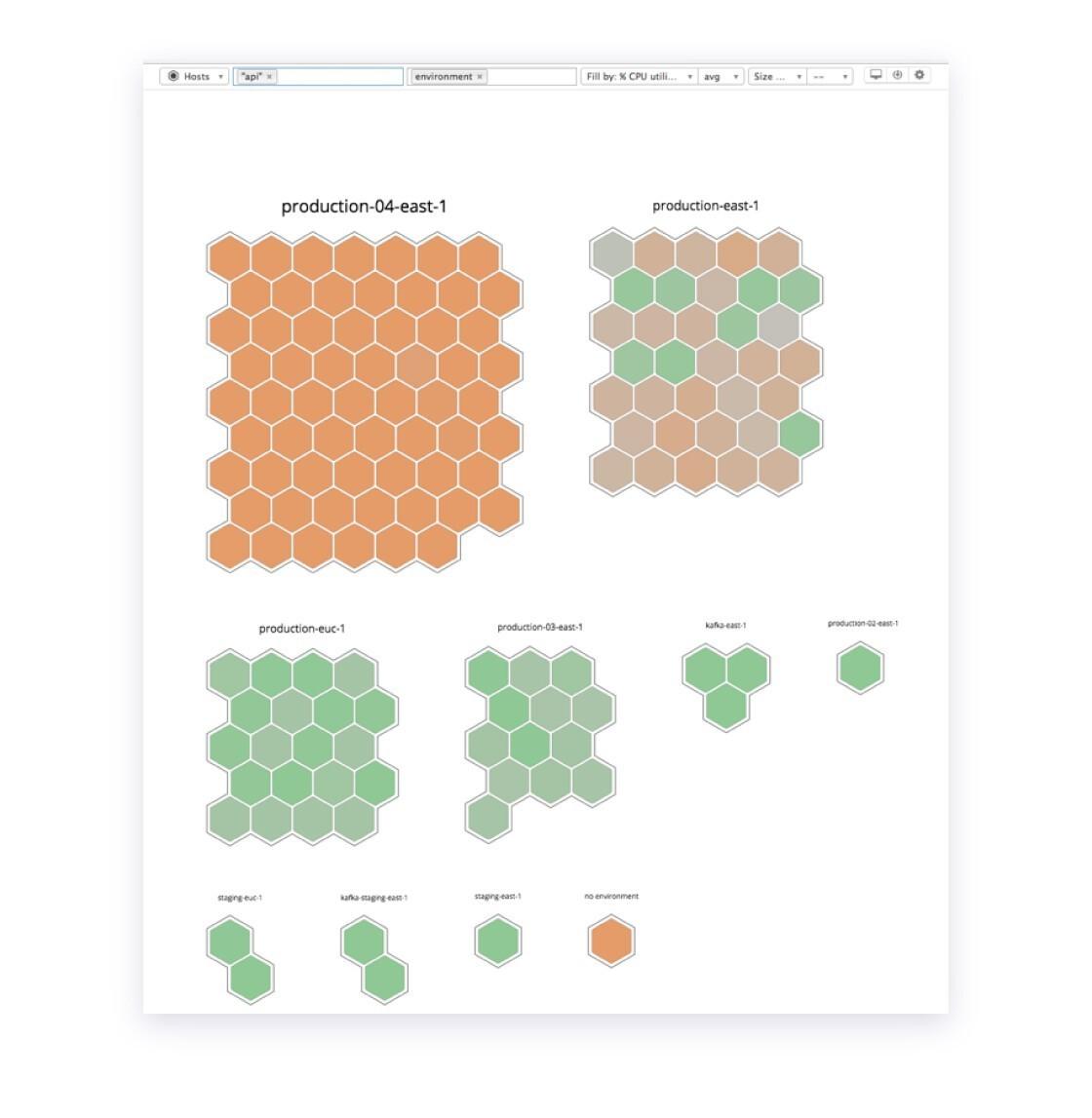
To give you some background, at Braze we scale our services by building different “clusters,” a collection of the systems that comprise our product, to create different installations that we can run individual customers on. We even build dedicated API servers or processing systems for specific customers. With more than 1.6 billion monthly active users, processing half a trillion pieces of data each month and sending more than a billion messages a day, this architecture helps us distribute load and improve our quality of service.
Because our API servers are stateless and return content to calling devices, we autoscale our SDK API fleet based on CPU utilization. By the time the page went off, our autoscale routine had already scaled up to nearly 60 c4.4xlarge EC2 servers (about $35k/mo of on-demand servers!), as this particular API was also handling about 20,000 API calls per second.
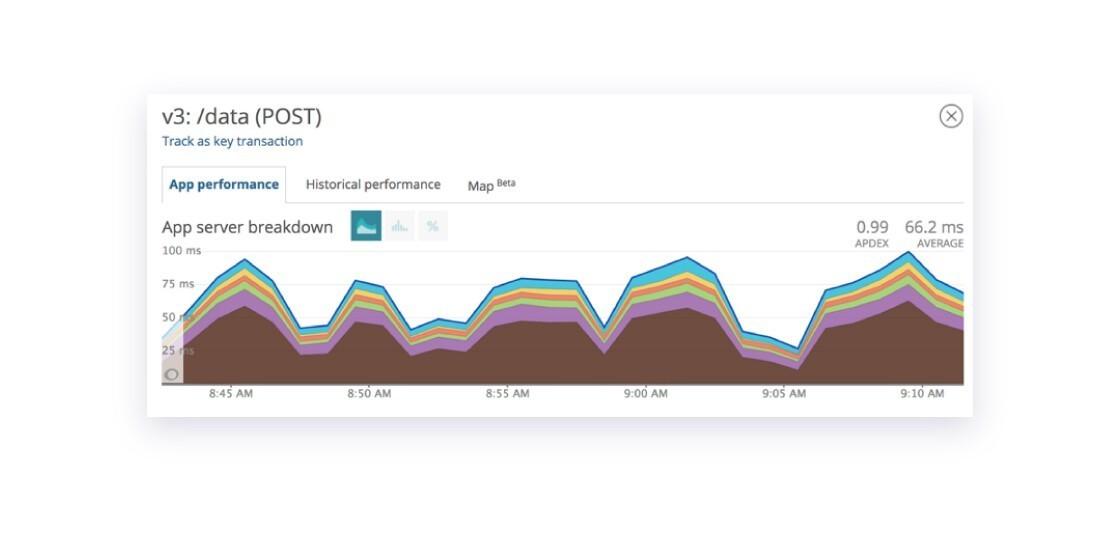
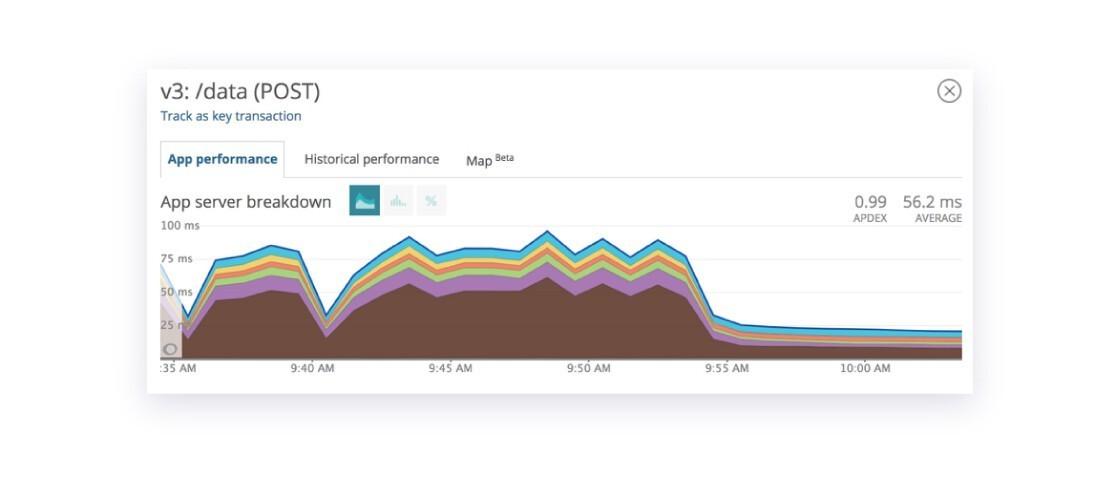
Digging a bit deeper into our Application Performance Monitoring (“APM”) tool, New Relic, we saw that average response times were about 5x the expected threshold, with much of the time spent in this brown segment that we had tagged “trigger_payloads.” We’ll get to that in a moment, because it was two o’clock in the morning and we needed to resolve the issue.
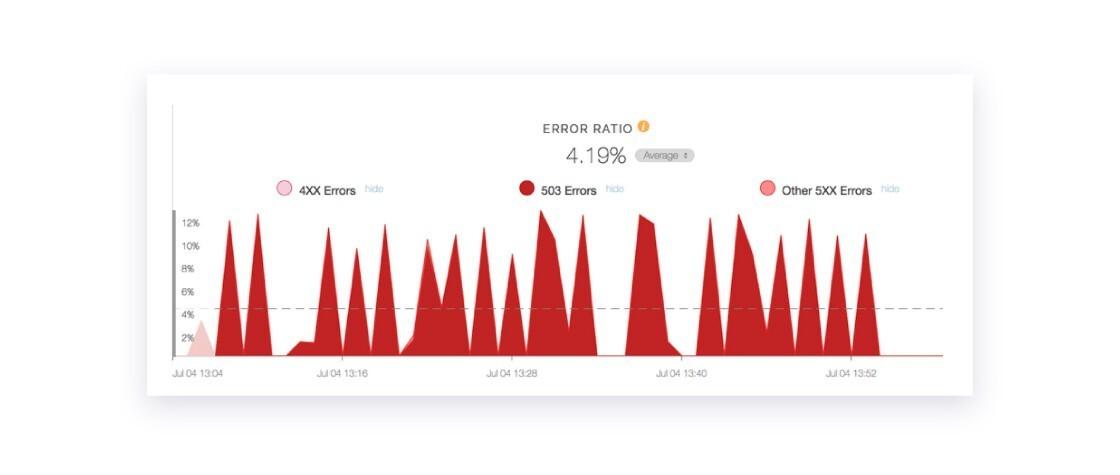
Per our runbook on CPU issues on our SDK API fleet, the first step is to try to add more CPU to stabilize the system. Despite tripling the number of active API servers, the issue did not go away. Our Fastly graphs indicated we were still receiving periodic bursts of 503s for this API endpoint for one of our customers.
Throwing more hardware at the problem wasn’t going to fix it. So let’s circle back to that “trigger_payload” section of our code.
Braze’s In-App Messages Product
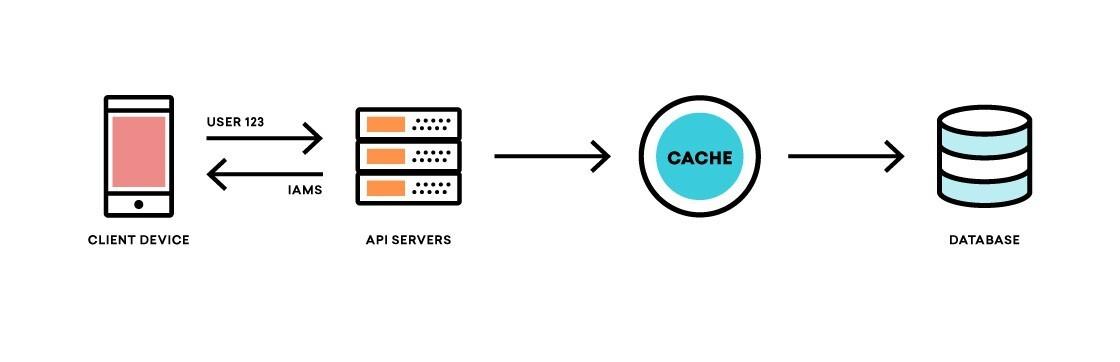
The “trigger_payloads” code block relates to Braze’s In-App Messaging product. The APIs that interoperate with our SDKs actually do a fair amount of complex processing. That’s because each of our SDKs, whether it’s for iOS, Android, Unity, the web, or any one of our dozen SDKs, have a business rule engine for when to show in-app messages (“IAMs”) to end users. Braze’s in-app messaging product allows our customers to deliver in real time in-app messages that are set to display when a certain event triggers. One customer may want to send down in-app messages to newly registered users who complete a purchase, while another could choose to target Spanish-speaking users who have not yet subscribed to push notifications when they listen to a song.
Each time an end user starts a session in one of our customers’ applications or websites, the Braze SDK requests IAMs that the user could be eligible for. The SDK will then download and unpack all of those in-app messages, along with their trigger criteria, such that as soon as the end user performs the event, the IAM is displayed without any additional latency. This provides a seamless product experience to our customers’ end users, allowing Braze to act as if it is part of their application.
For the API layer, having such a flexible in-app message product means that determining which IAMs to send down can be fairly CPU-intensive. On each API call, the API determines the end user on the device making the request, reads all possible in-app messages for that application, and then computes eligibility criteria for the user to determine which IAMs to send down. There is no limit on how many different in-app messages our customers can have active at a time. Using the set of all possible in-app messages, the API reads and processes the target criteria and stores it in memcached with a 90-second TTL (or, Time-to-live) so other API processes can use that computed state.
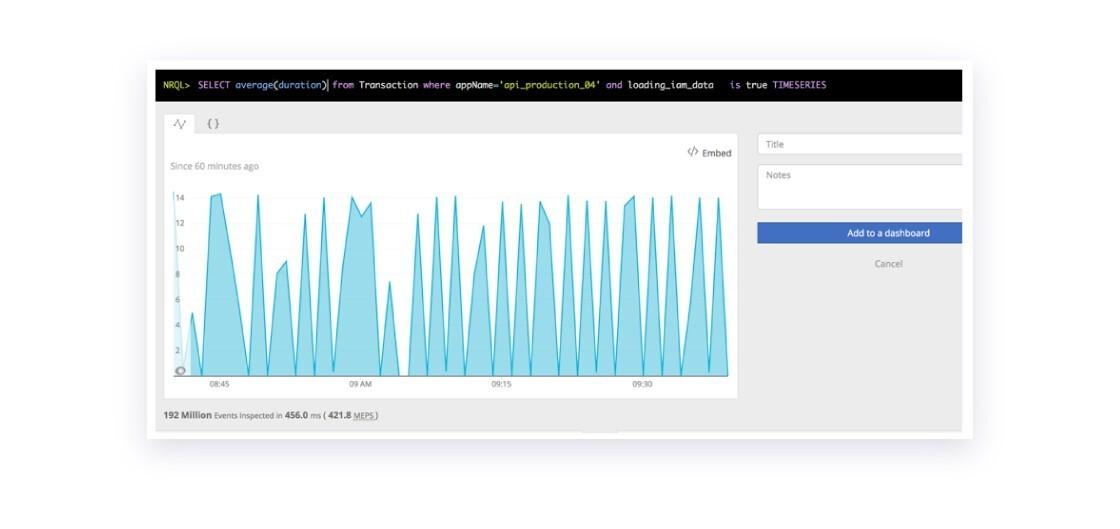
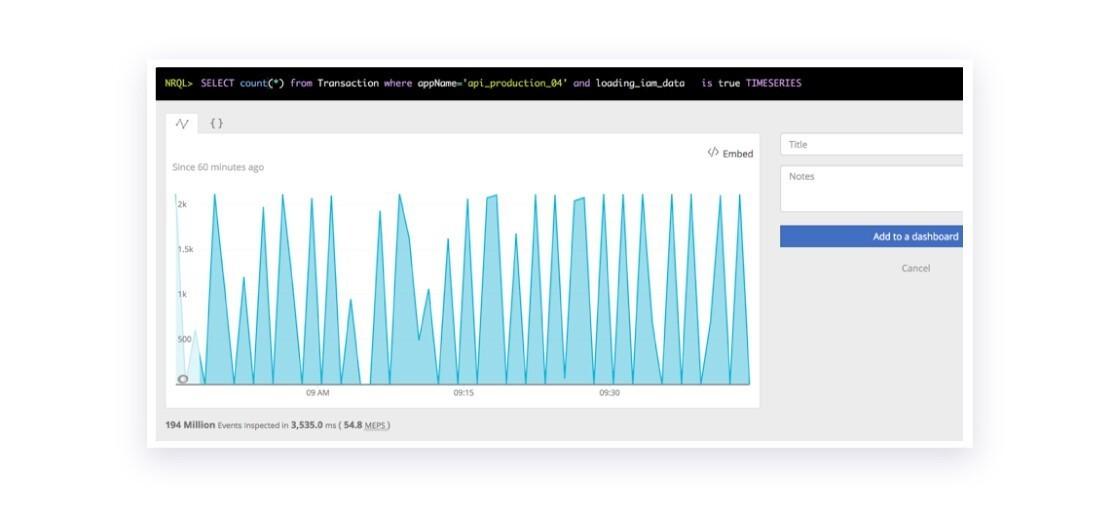
At Braze, we rely on a lot on APM tools for debugging and troubleshooting. When we dug into the code which generated this one particular customer’s in-app messages, we noticed that while the average response time from our API was 66ms, every 90 seconds we’d see about 6,000 API calls take more than 14 seconds! Each time this happened, it caused a brief surge in HTTP 503 errors, as our backend was not able to serve all the oncoming traffic.
Summarizing all that we knew:
- The API servers affected were receiving a large number of requests, more than 20,000 API calls per second from a high-volume customer
- This customer had added many new in-app messages with sophisticated targeting rules
- Every 90 seconds, about 6,000 API calls took 14 seconds to compute
This was a cache stampeding herd issue: as soon as the cache expired, we immediately had 6,000 requests take 14 seconds trying to populate it. Of course this won’t scale!
Preventing the Stampeding Herd with Concurrency Control
How did we fix this? Redis. At Braze, we use Redis for, among other things, concurrency control in our distributed systems. We decided to use Redis to control the refresh rate of our cache. Redis is an in-memory data store that is blazing fast. It also has atomic properties, which makes it great for creating locks and semaphores for concurrency control.
We modified our caching code to extend the memcached TTL from 90 seconds to 180 seconds, using Redis to have one process refresh the cache every 90 seconds. This way, we didn’t lose any fidelity in how often we recalculated state, but had the benefit of decreasing concurrency.
The effects were immediate, drastic, and incredible. API requests that loaded in-app message state dropped from about 6,000 every 90 seconds to one. (This makes sense because we used a global lock!)
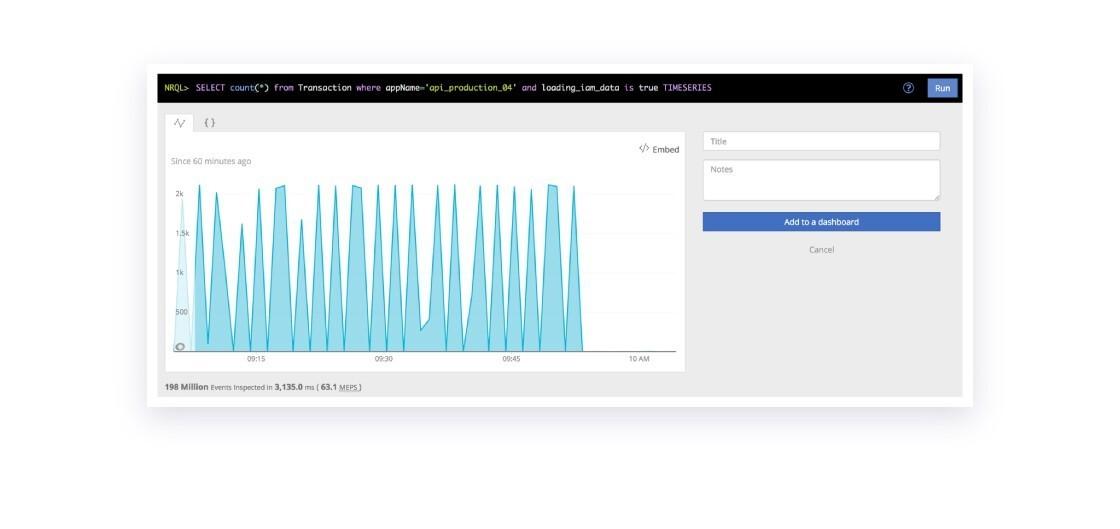
Notably, because the reduced concurrency stabilized the CPU load, the computation only took about three seconds instead of 14.
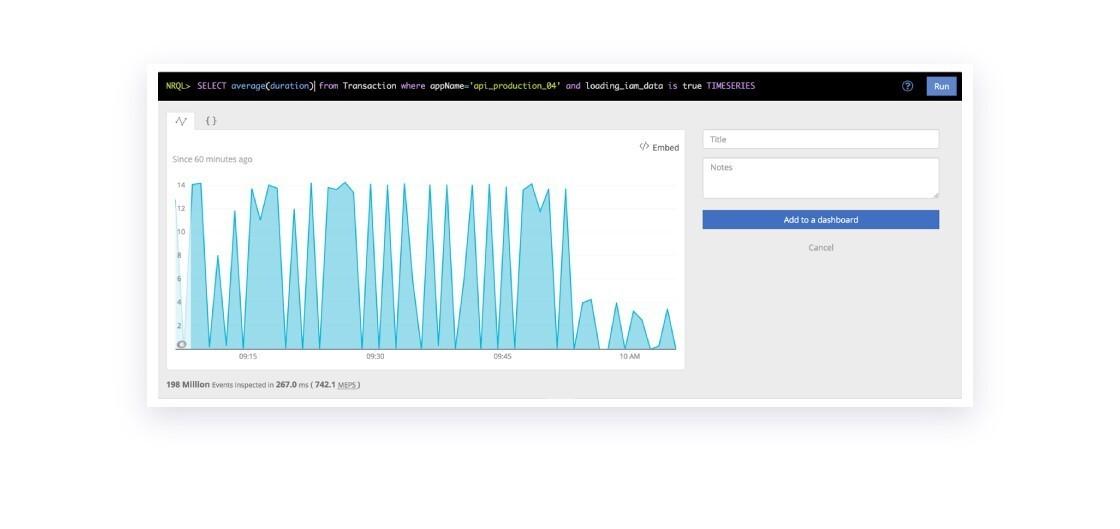
With the latency stabilized, we were able to drop back down the number of API servers we had online to the original pool size.
We have found this pattern to be such a useful tool that we have generalized the pattern to control the refresh rate of a cache at Braze’s high scale.
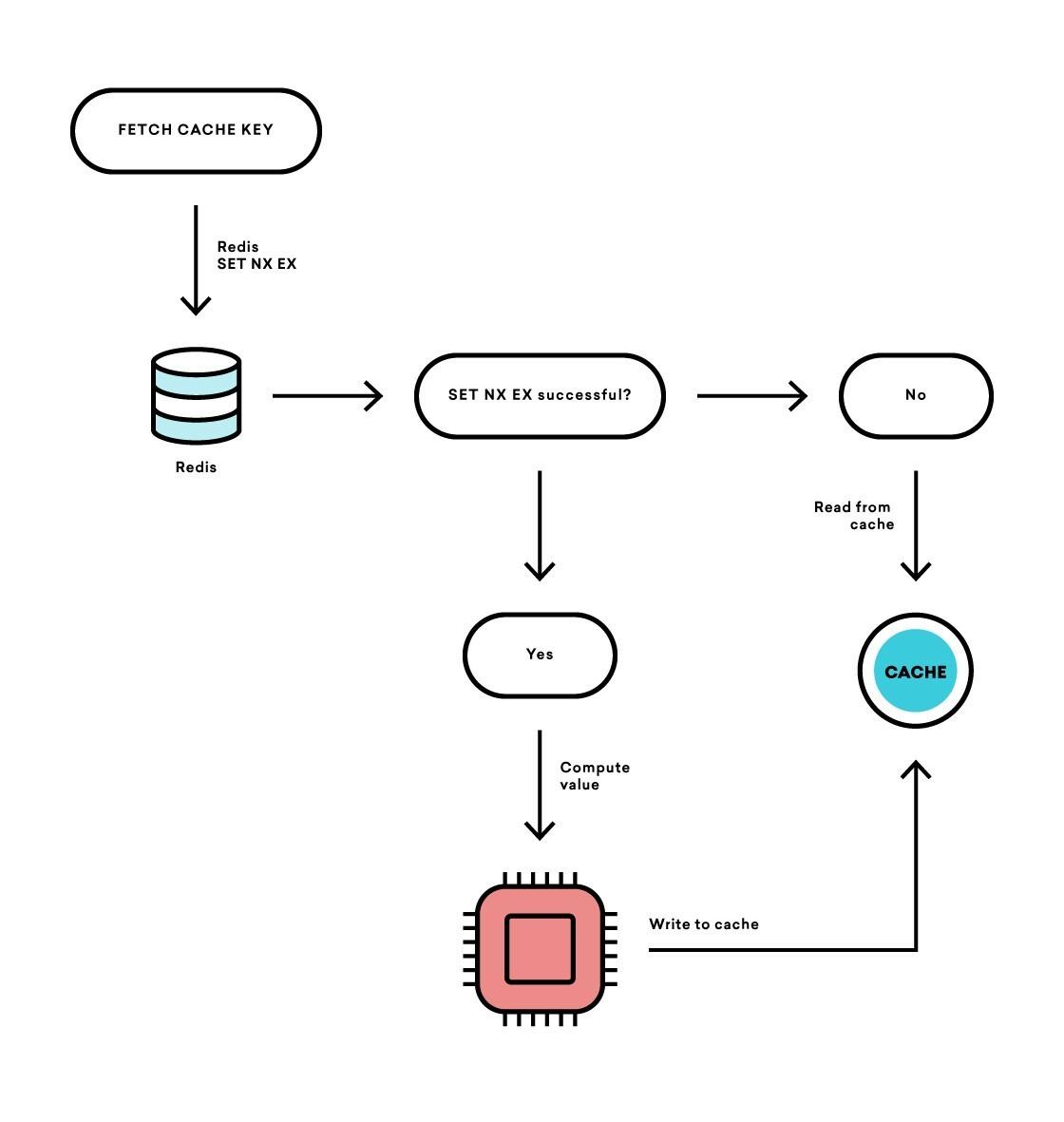
While a bit more complex, this reduced concurrency caching strategy, known also as “refresh-ahead caching,” can resolve issues that crop up when at a massive scale.
Interested in working at Braze? Check out our current job openings!
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.
Related Content
 Article7 min read
Article7 min readEmail deliverability across APAC: Navigating a diverse digital landscape
July 31, 2026 Article4 min read
Article4 min readThe new CNIL recommendations: Email tracking pixels in France
July 30, 2026 Article6 min read
Article6 min readBuilt to Scale: Announcing the 10 Startups Joining Cohort 6 of Braze Product Grant Program
July 30, 2026