Don’t Forget About Network Scalability!
Published on October 29, 2018/Last edited on October 29, 2018/7 min read

Jon Hyman
CTO, BrazeBraze, formerly Appboy, handles a tremendous amount of scale in our systems, peaking at hundreds of thousands of API calls per second and running thousands of databases and application servers. This post is about how our growth broke our physical networking hardware and how we moved our networking layer to the cloud.
Braze Architecture, Circa 2015
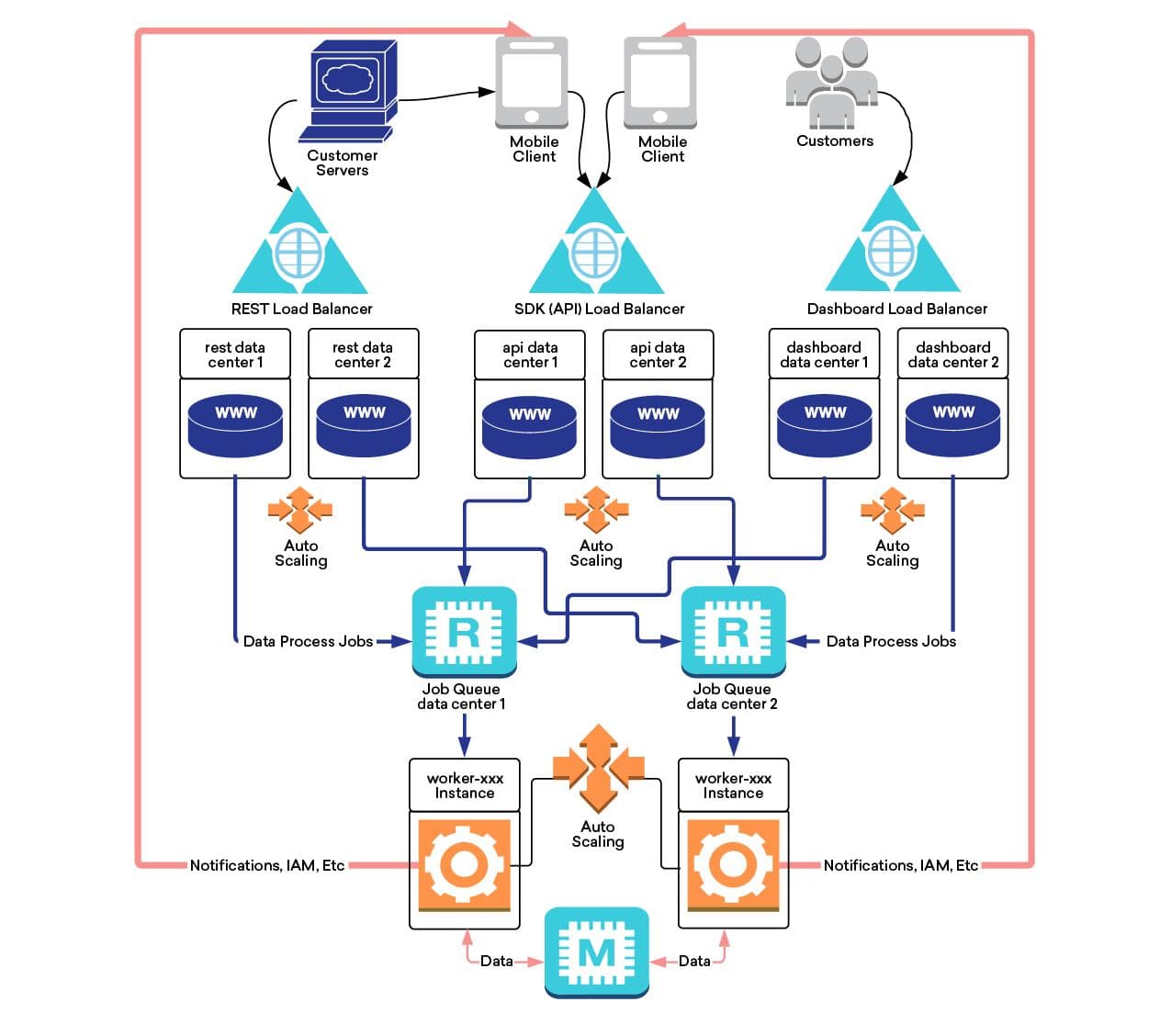
Data flows over an encrypted HTTPS connection to our APIs, which ingest the data and put it in a job queue. It is then instantly processed by a fleet of servers which determine how this new information changes our understanding of the audience segments this user belongs to, or if a message should be triggered. For example, customers may set up a business rule such as, “When a user makes a purchase, email them a reminder a week later to rate their experience if they haven’t already completed the survey.”
Back in 2015, the Braze platform was hosted at Rackspace. We started the company in 2011, when the cloud landscape was much less mature than it is today. Google, Amazon, and Azure did not offer as wide an array of servers as they do today. We knew that Braze had the potential to achieve massive scale. At the time, what we thought made the most sense was to have a hybrid physical and virtual approach, so we’d be able to use the consistency, performance, and stability of bare metal single-tenant servers, while having the elasticity of a cloud offering to scale as needed.
To do this, we worked with Rackspace to set up our approach. The hybrid model uses something called RackConnect (see diagram for explanation of this configuration).
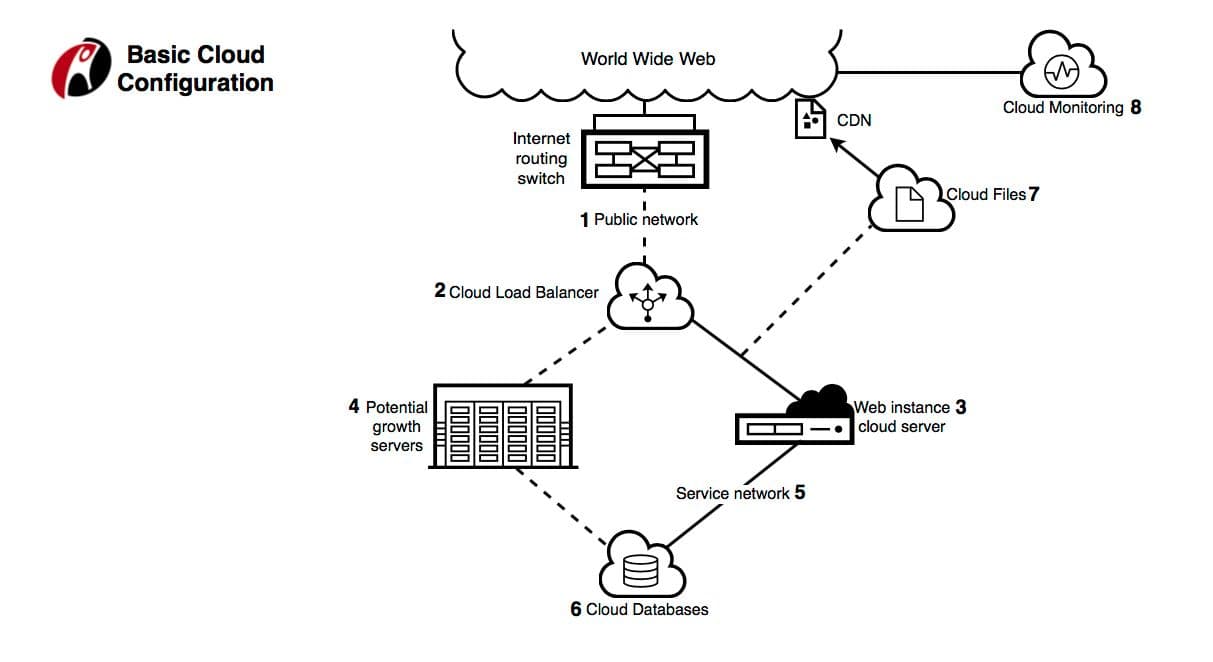
With RackConnect, you have a physical F5 load balancer and a physical firewall. We used a redundant pair of F5 5200V load balancers, which can handle 21,000 SSL transactions per second with 2k SSL keys and about 700k connections per second. Our firewall was a Cisco 5585, able to handle about 50,000 connections per second and about 1 million concurrent connections. We had a 1 gigabit per second network switch, allowing for 1gbps traffic in each direction.
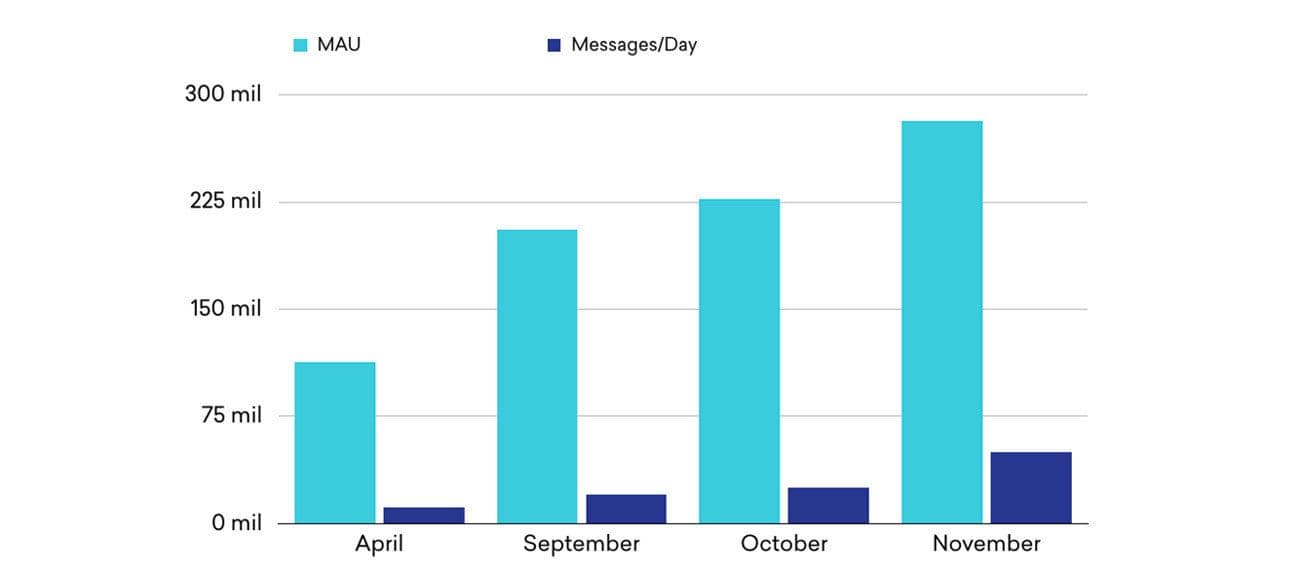
In 2015, our product was seeing massive growth: In the few months between April and November, Braze grew from more than 90 million monthly active users to nearly 300 million. That’s roughly adding the entire populations of Japan and Canada on to Braze’s platform in a seven-month period. Our message volume was also increasing, from around 20 million messages sent per day to about 60 million.
Until this point, our customers were not businesses that sent large volumes of messages at one time. We didn’t have customers sending 10 million push notifications, or 20 million emails, in a single scheduled campaign. But now with this growth, we did. And when they sent those messages out, we felt it at the network.
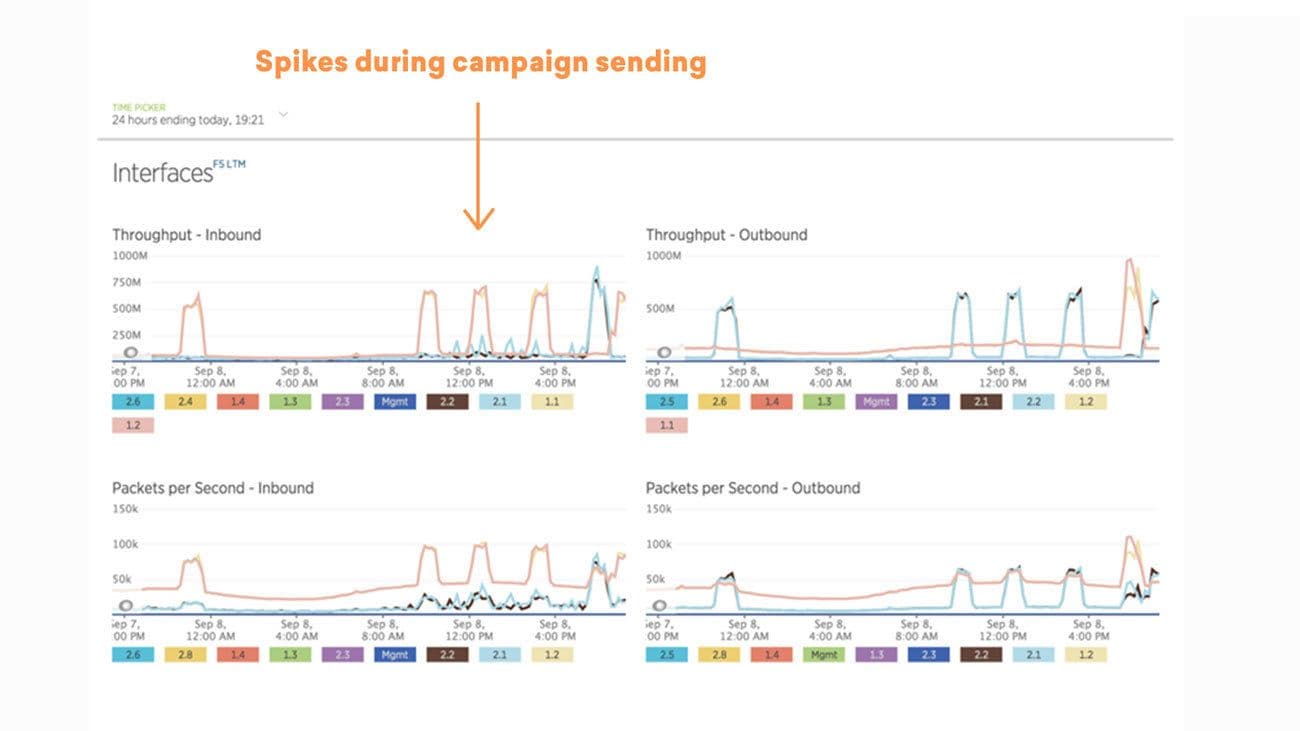
Here’s a daily view of our network from around that time. Network traffic is fairly low until it jumps up when a customer sends out a large campaign.
Zooming in on one of the spikes, we see that we started to hit that 1gbps limit and saturate our network.
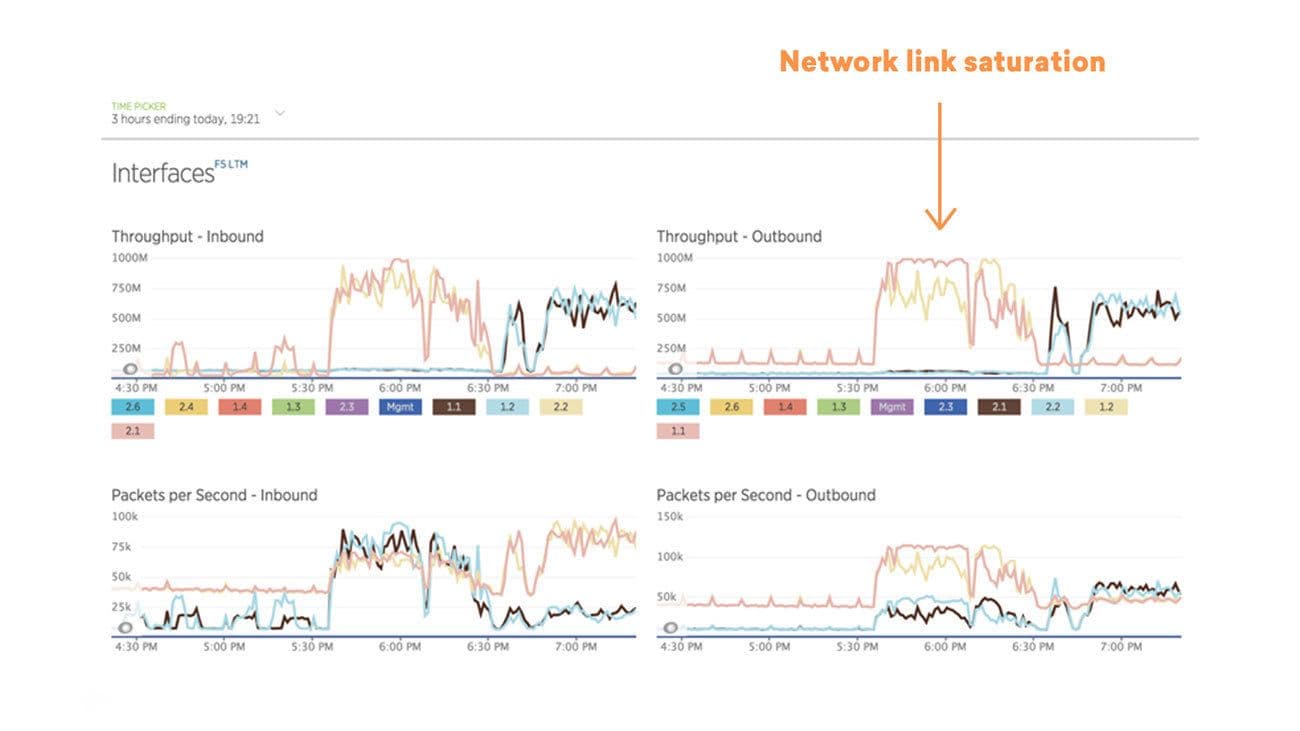
Sending out a large number of messages, in particular push notifications, can also have a thundering-herd-like effect of API calls back to Braze. Imagine that 5 million people receive a push notification, their phones vibrate, they look at it, and tap the notification. Now there’s also a flurry of inbound activity coming into the network!
It wasn’t just our network that was having a hard time keeping up, our firewall was also quite unhappy during these spikes, hitting high CPU load.
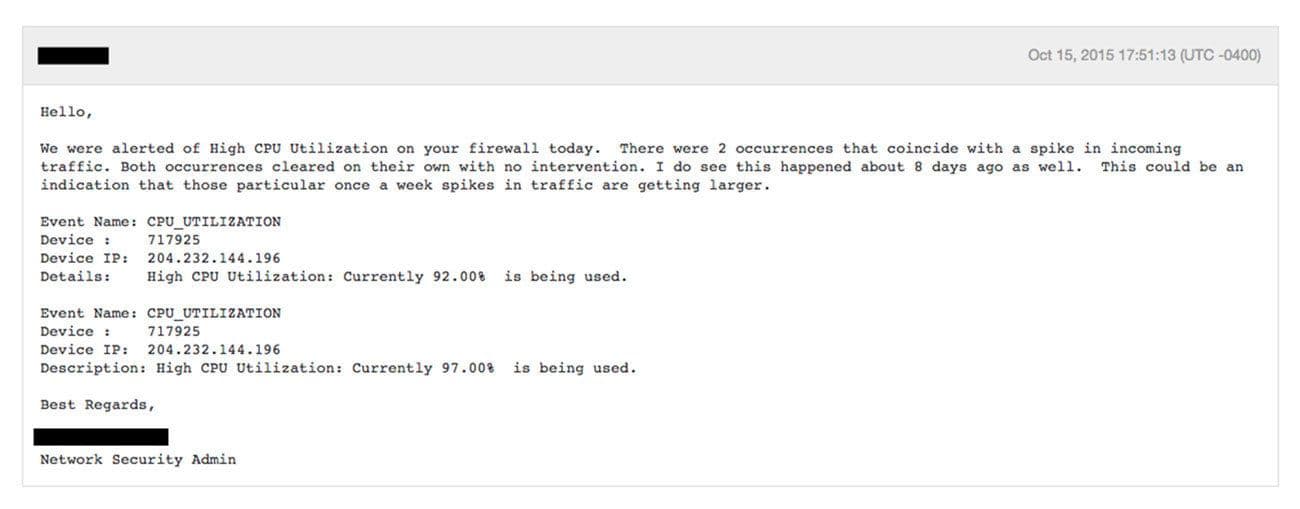
If a firewall gets to high CPU utilization, it can stop filtering packets and begin to drop new incoming traffic. We started to see some instances of this, with sporadic and highly unpredictable network connection errors in our APIs during these big campaign sends.
We needed to do something, and do it fast. Rackspace suggested we move to more powerful hardware: Viprion Series 2250 blade load balancers, hardware that would have cost $51,588/month. There were two problems with this:
- The price was extremely high for a growing startup. I found it hard to stomach paying that much for networking equipment.
- It would simply take too long. These load balancers weren’t in stock, so they had to be ordered, racked, and then we had to fail over to them, a process that could take about two weeks.
Then we thought up an alternative idea: What if we built a series of cloud load balancers and offloaded some of our network traffic to them? Perhaps that would decrease CPU load from our F5s and firewall.
We built about 20 load balancers and started offloading a single digit percent of our traffic to them.
After trying this, the next day we got an email from Rackspace support saying that we were adversely affecting their IAD data center due to network traffic and had to suspend a half a dozen cloud load balancers to attempt recovery of their systems.
We felt backed into a corner here—and as an engineer you spend so much time thinking about scalability. Ensuring that your database can scale. Focusing on performance of your application server. The network was one area I hadn’t considered, and also one where I felt we had the least amount of control at the time.
Just when we thought things couldn’t get worse, they did. During another large campaign send, we had what looked like a huge denial of service attack:
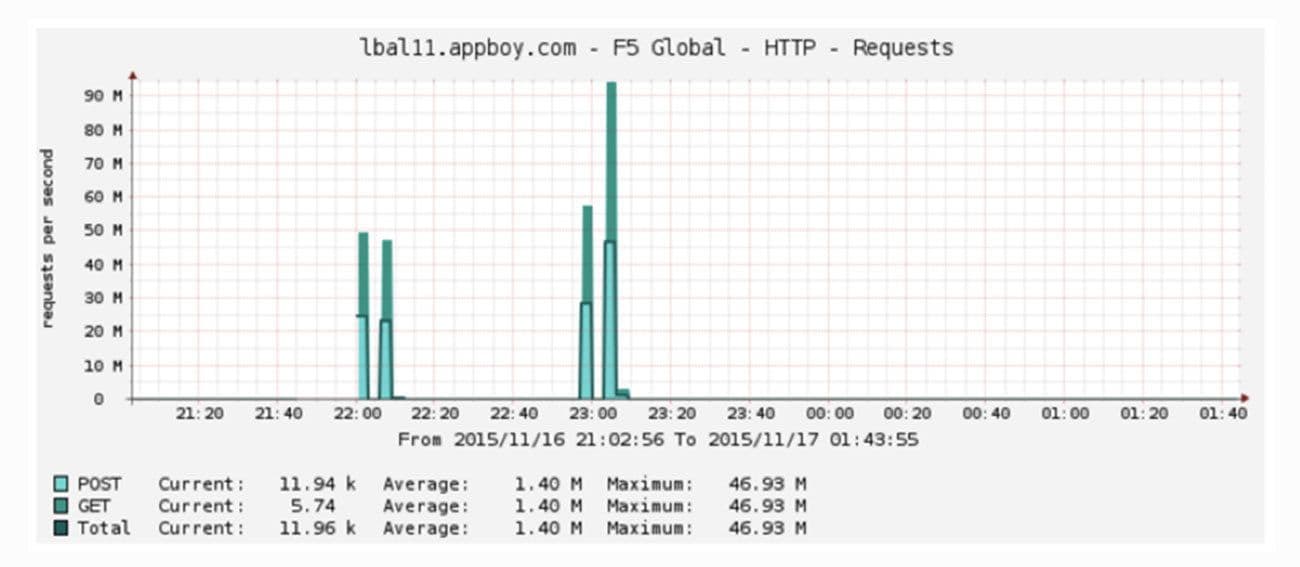
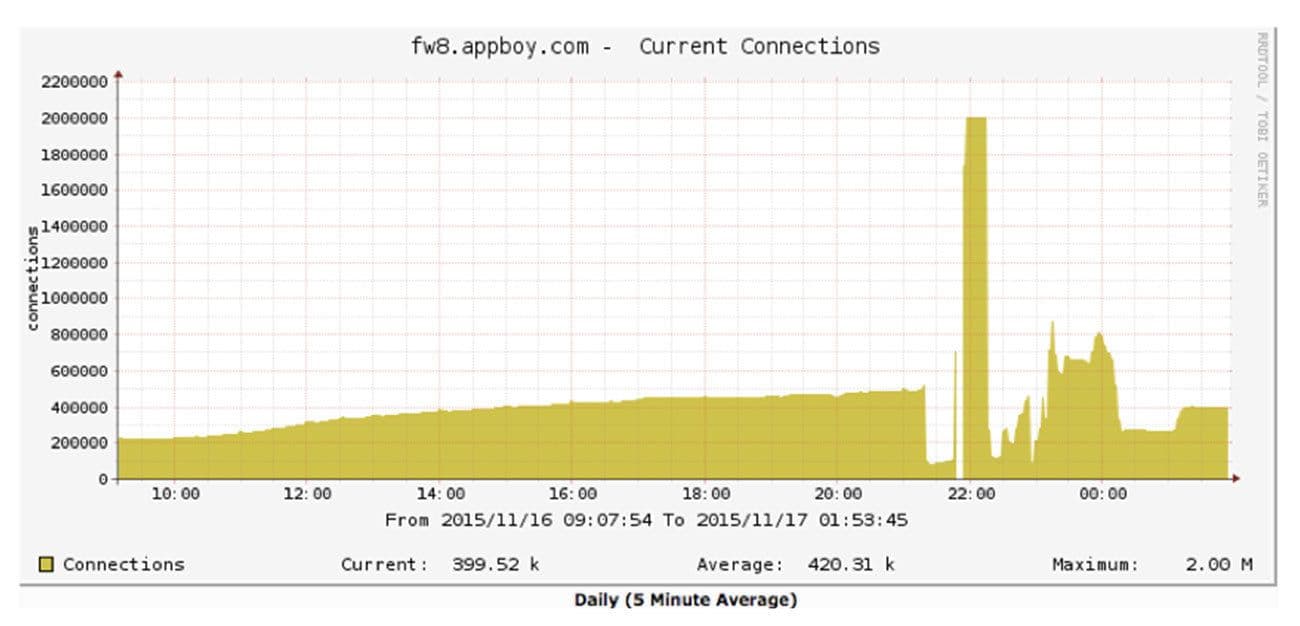
More than 100 million requests per second on our load balancer?! Over 2 million concurrent connections? We were failing over the load balancers and blocking traffic to get everything to stabilize. We escalated to the F5 engineering team only to discover that we had hit a bug in the F5s: once CPU utilization got high enough and connections dropped, the F5s’ persistent session handling kicked in and got in an infinite loop of trying to re-establish connectivity.
One thing was extremely clear: We needed to get rid of the F5s.
How We Fixed the Network
We called up Fastly, an edge cloud platform, to help us with our network scalability. The problem was all due to the large amount of SSL traffic going through the F5s. Everything sent to and from Braze is encrypted, and the F5 was graded to handle 21,000 SSL transactions per second using a 2k encryption key. To give you an idea of how CPU–-intensive SSL transactions are, that F5 can comparatively handle 7 million L4 HTTP transactions per second!
While 2048-bit SSL keys are secure, we had wanted to keep a 4096-bit SSL key between end-user devices and our network. The plan we came up with was to have Fastly handle SSL termination from mobile devices and websites, and then pipe the traffic back to our load balancer using a verified 2048-bit SSL key. We worked with Fastly to establish trust of our certificate so they validated our 2k cert. We pipelined connections back to our F5 to minimize the TLS transactions our F5 had to do and decrease the number of connections to our firewall.
This strategy instantly dropped the load from our F5s and our firewall, which gave us the breathing room to grow and get off all the physical hardware. We moved to AWS 45 days later. With Fastly and AWS, we haven’t had to think about the volume of SSL transactions since.
The impact for our customers was that our message sending and APIs became much more reliable, even as we have continued to grow. Today, we help our customers engage more than 1.4 billion monthly active users and deliver tens of billions of messages each month, all without worrying about scaling our network.
Interested in working on highly scalable distributed systems? We’re hiring!
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.
Related Content
 Article3 min read
Article3 min readJuly 2026 Bonfire Marketer of the Month: Cleo’s Holly Jacobson
July 27, 2026 Article8 min read
Article8 min readClosing deals, driving growth for customers, and the team behind it: Life as an Account Executive at Braze
July 17, 2026 Article12 min read
Article12 min readBrazeAI™ marketing tools: The complete guide to AI-powered customer engagement
July 17, 2026