How Braze Overcame Data Leakage to Build Predictive Churn
Published on December 21, 2020/Last edited on December 21, 2020/8 min read


Matt Willet-Jeffries
Manager, Product Engineering, BrazeEarlier this year, Braze announced the launch of Predictive Churn, the first feature in our new Predictive Suite. This collection of predictive analytics tools is intended to make it easier for brands to understand and proactively identify trends and insights about their audience, supporting smart customer engagement and helping companies build stronger relationships with their users.
On its face, Predictive Churn is a simple feature. For it to work successfully, this tool must train a model to identify individual customers who are likely to churn and then be able to apply that model to a larger population of users. This allows brands to identify users in their audience who are particularly likely to lapse and makes it possible for them to reach those users with targeted campaigns to increase retention. Behind the scenes, however, there’s a hidden wealth of complexity that ended up shaping the fundamental patterns and infrastructure that Predictive Churn is built on.
Let’s take a look at the process that led us here and one of the challenges we faced in making Predictive Churn function effectively: Data leakage.
Setting the Stage: Understanding the Challenges in Building Predictive Churn
When we first began working on the development of Predictive Churn, our primary goal was to determine whether building this feature was even possible—that is, to make sure that we could take user data, feed it into a model, and accurately identify the users who were most likely to stop engaging with a given brand. In a classic engineering twist, however, this early goal ended up giving way to deeper and more enduring concerns.
From early on, we knew that churn prediction and other forms of behavior prediction were possible for many of our customers, but as we dug deeper it became clear that the difficulties associated with this potential feature weren’t related to the modeling itself. Instead, the central issue—associated with the Predictive Churn models’ implementations—occurred at the crossroads between software engineering and data science.
For Predictive Churn to provide real value to our customers, two things needed to be true. First, that our predictive models could be designed by each customer using the feature to match their brand’s definition of churn. Second, that these models could be trained immediately after a definition was finalized. But we found that these requirements had the unanticipated side effect of limiting the data that we were able to use to train our predictive models.
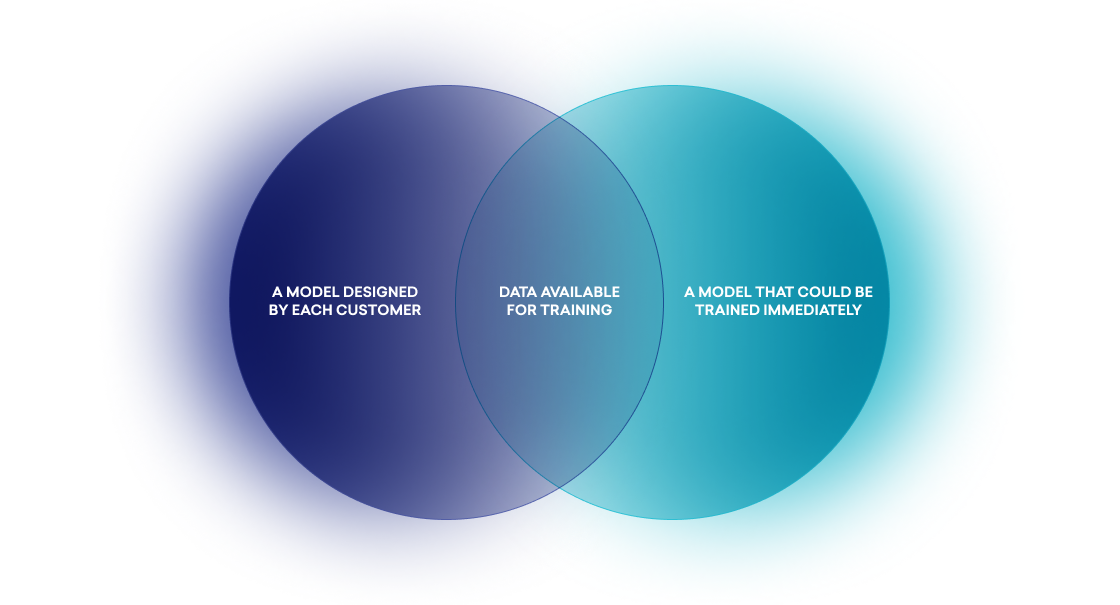
The data we used to train our models had to be rapidly accessible and capable of being flexibly filtered to meet custom-designed audience definitions, forcing us to rely on stateful user data and blocking us from selecting cohorts in advance. The upshot? In order to produce the feature sets and labels we needed, we had to select users based on their known histories, and then revert their state with those histories, a process we called “look back” internally.
Look back works by storing user event histories and then manipulating stateful fields using these histories to build accurate historic user states. This process allowed us to reuse existing filtering to select user cohorts for targeting and training that supported our ability to rapidly pull historically accurate audiences. Then, we were able to swiftly build the features and labels we needed to train with them. But this approach wasn’t without costs. One big issue? It opened the door for one of the most pervasive problems in predictive modeling—that is, data leakage.
Data Leakage: What It Is and Why It Matters
A supervised predictive model relies on a set of historic inputs and outcomes in order to learn how to predict future outcomes; so if historic inputs become biased or altered by their associated known outcomes, the performance of the underlying predictive model can be substantially damaged in practice. This phenomenon, known as data leakage, can occur in any situation when a predictive model is inadvertently given access to information during training that it wouldn’t have access to during prediction time.
Think of it as the model “cheating” on the test by knowing the answers in advance—and then having to take a midterm without any of that information. Leakage effectively lets the model cheat at training time, but because the information at its disposal isn’t there when the time comes for it to actually predict things, it tends to cause models to overperform during training and then underperform at prediction time.
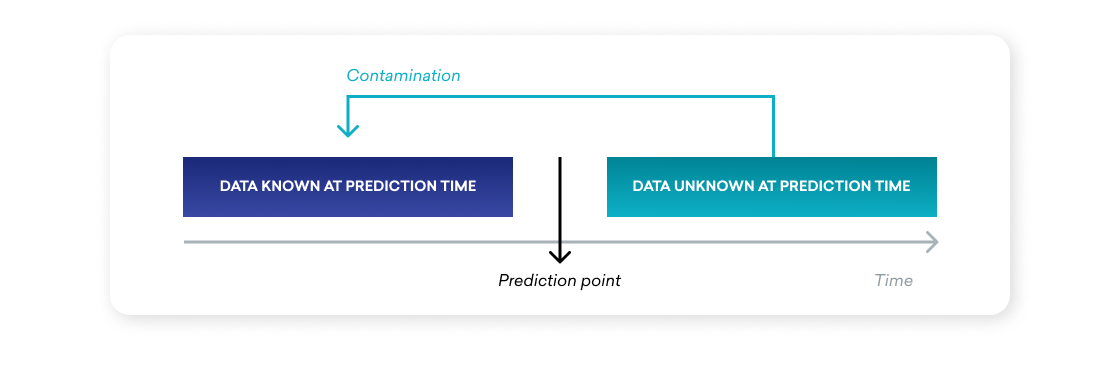
This dynamic can undermine the effectiveness of the predictive model—as well as users’ confidence in the model, potentially leading to less usage or lower adoption of the model overall. Which, if you’re going to spend the time and energy it takes to build a model like this, is something of a worst-case scenario.
How Braze Used Rapid Validation to Address Data Leakage
With Predictive Churn, our use of look back meant that the user object we leveraged to build our feature sets and selected for training could contain information that ultimately wouldn’t be available to the model at prediction time. While we were eventually able to insulate training from most data leakage via rigorous testing, it became apparent that we needed a protocol to prevent code and model changes from reintroducing data leakage into the models that make up Predictive Churn.
During the process of creating Predictive Churn, we found that data leakage can stem from almost any stage of the training process and can manifest in complex and surprising ways. In addition, this leakage often proved to be undetectable in unit tests and simple integrations, so we decided to examine more active approaches to detecting and addressing it.
There are many potential ways to identify data leakage, but the most straightforward involves the use of validation—that is, the process of testing predictions against their outcomes as part of post-prediction analysis. Just as you test a supervised predictive model with scores mapped to outcomes at training time, you can verify a model’s performance at prediction time by collecting scores, waiting out the time window of the prediction, and then mapping the collected scores against determined outcomes. Because the features used to generate the scores for validation couldn’t have contained data leakage, it becomes possible to use differences between performance at testing and validation to detect leakage.
With this approach in mind, we introduced a validation stage into our modeling process for Predictive Churn. During this stage, we have a job pipeline that collects the score of a randomly selected sample of the prediction audience at prediction time and then schedules follow-up jobs to determine the final outcomes for that cohort. We subsequently measure the success of the prediction and compare it to the performance expectations described by the model at training during the testing phase. This ensures that significant changes in performance can then be used as an alarm for problematic data leakage.
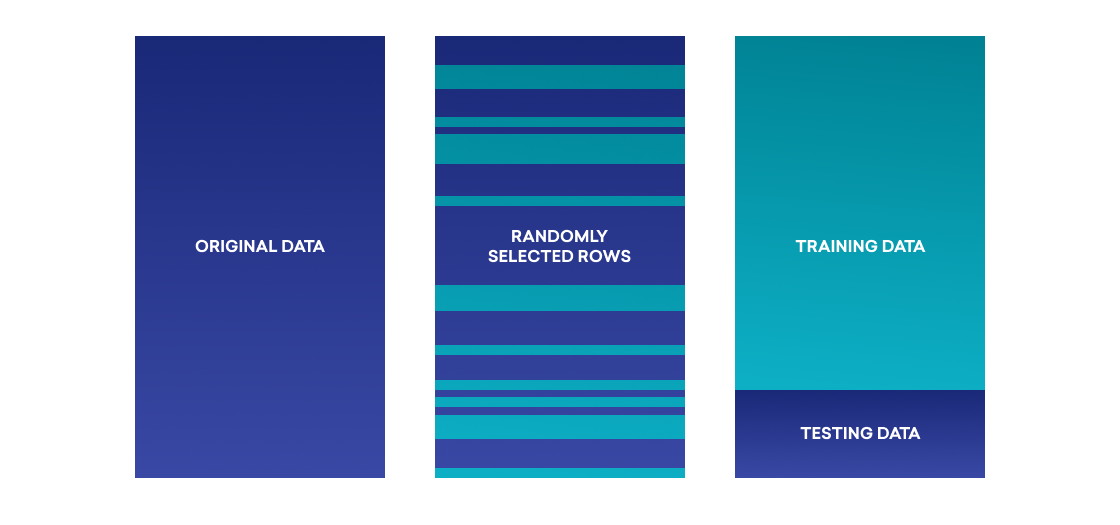
By leveraging this proactive approach, we gained a general heartbeat metric on the health of our models and a means of testing changes in an insulated fashion. However, it doesn’t satisfy all the needs in this area. Because validation must wait for a prediction’s time window to pass before final outcomes can accurately be determined, it can be quite slow, limiting the cadence at which code and model improvements can be introduced. Most predictive models at Braze are built to make predictions over a two-week time period, so relying on live validation alone to test changes has the potential to delay development by multiple weeks.
To address this complication, we decided to collect historic snapshots of user cohorts, allowing us to rapidly run validation end to end. Reusing our training and prediction pipelines, we pulled anonymized user data for typical model definitions at both training time and validation time, and then stored that data in compact serialized files on Amazon S3. By pulling from these files, we were able to train a new model and validate its predictions in mere minutes. So by triggering this process as part of our continuous integration (CI)/continuous delivery (CD) protocol, we effectively introduced runnable validation that removes the pain of having to wait for real-life outcomes before any action can be taken. While this approach is relatively new and still in active development here at Braze, it’s proven able to yield rapid and accurate results.
Final Thoughts
With these layers of automation in place, data leakage has thankfully shrunk as an issue for Predictive Churn. While still a major concern during the model development phase, we’ve effectively developed safety rails that drastically reduce the risk of leakage and allow us to keep close eyes on the integrity of our predictive models.
To learn more about Predictive Churn and what it makes possible for customer engagement, check out our overview article here.
Interested in working at Braze? Check out our current job openings!
Be Absolutely Engaging.™
Sign up for regular updates from Braze.
Related Content
 Article7 min read
Article7 min readEmail deliverability across APAC: Navigating a diverse digital landscape
July 31, 2026 Article4 min read
Article4 min readThe new CNIL recommendations: Email tracking pixels in France
July 30, 2026 Article6 min read
Article6 min readBuilt to Scale: Announcing the 10 Startups Joining Cohort 6 of Braze Product Grant Program
July 30, 2026