Turning the Page: How Braze Transformed Our Process for Handling Pages
Published on March 25, 2020/Last edited on March 25, 2020/12 min read


Brian Wheeler
Senior Director, Engineering at BrazeFor most technology companies, paging is a fact of life. When a significant issue crops up with your software, you need people who can act quickly and respond to it in order to minimize the impact on the customers you serve. How your organization plans for and manages that process can have a major impact on how successfully you’re able to respond to incidents—and how much you’re able to minimize the toll these situations take on your team.
At Braze, we’ve been working over the last year to execute major changes in the way we handle pages. Historically, our DevOps team has stood on the frontlines when it comes to pages—even if it was the application code, not the infrastructure, causing issues—and there weren’t clear pathways to escalate to the Product Engineering team. This was never an ideal approach, but by the beginning of last year it became clear that it could no longer scale with our organization; we needed to find ways to ensure that Product Engineering could provide 24/7 support of the code we own. Separately, our organization had ambitious goals for increasing the stability and performance of our system. We’d set ambitious Service Level Objectives (SLOs) and needed to be able to ensure that when our system had problems, they were fixed fast. Braze has been growing swiftly for years and we now send more than two billion messages (and ingest billions and billions of events) each day, so this necessitated the creation of a much more robust ecosystem for training, prioritization, and support in connection with our massively scaled, real-time system.
On its own, this sort of organization-wide change would require a major effort. But at Braze, there’s a wrinkle that complicates things: The center of gravity within our infrastructure is a monolith. With a standard service architecture, a page is sent from one service; the team that owns that particular service is then charged with responding. With a monolith, however, ownership of a given page can be ambiguous. Because multiple Braze teams own code within that monolith, one major issue we had to grapple with was how to ensure that all pages were routed to the appropriate team.
Read on for the story of how we rolled out effective coverage for our monolith, by taking the following steps:
- Optimizing our process, infrastructure, and code by adhering to the principles of continuous improvement, incremental change, and automation
- Leveraging Agile workflows and conducting a daily review of page handling to ensure root cause analysis for every page...and that action being taken to prevent recurrences
- Organizational change leveraging insights from cross-functional committees
Step One: Organizing a Committee to Drive Results
We started out this initiative by drawing inspiration from past successes and creating a cross-functional committee to diagnose, discuss, and implement the changes we needed to make to our paging system. I can’t emphasize enough how important these sorts of committees have been when it comes to driving organizational change. Having representatives from many different teams across multiple different functions (and levels of seniority) has resulted in immense benefits, including:
- More representative, higher quantity, and higher quality input throughout the process
- The solicitation and delivery of key insights from different teams on an ongoing basis
- Preparing members of teams across the company for the changes the committee expects to make in advance, to reduce friction and improve results
While Braze doesn’t explicitly follow Amazon’s famous “two pizzas” rule when it comes to meeting size, we made an effort to ensure that all committees were small enough that real dialogue was possible. (What that looks like, however, may well differ from organization to organization.) However, because this effort required a significant amount of cross-team sorting and routing of pages, as well as team-specific process updates, it was essential for us to ensure we had stakeholders from all the relevant teams involved and armed with the context they needed to help roll out changes.
Step Two: Supporting What We Build
During the committee’s initial meetings, we all dove headfirst into diagnosing the main issues at play:
- A number of the pages being sent were triggered by application code...but were being handled by teammates who hadn’t written that code
- A small subset of the overall engineering headcount was responsible for all of the company’s off-hours support
- Braze had SLO goals that could only be met with expanded support
- In some cases, we weren’t following up effectively on pages, leading to preventable recurrences
It became clear that the status quo needed to change. If an engineer on the Product Engineering team writes non-performant code that, for instance, caused our queueing system to send out a page overnight, the DevOps team members who respond are going to lack key context on how to fix that issue and clarity around pathways to resolving recurrences. Given that, we needed the teams who wrote a given piece of code to support it fully in production—both in a triage capacity and when it came to executing on preventive steps and enhanced functionality.
Step Three: Determining Who Owns What
Once we agreed that teams within our organization needed to own and provide 24/7 support for their discrete, separately deployed and tested libraries, services, and components, we needed to figure out what steps to take to get there. The first? Separating DevOps pages and Product Engineering pages. After all, we can’t route pages by team until we’ve laid a foundation by routing them by division.
To execute on that first step, we reorganized our entire PagerDuty configuration to ensure that we had:
- PagerDuty services that represent the entirety of our infrastructure
- Pages that route to our DevOps escalation
- Pages that route to our Product Engineering escalation
What did that look like? Well, for example, it meant that DevOps received the pages related to database failures, Product Engineering received the pages for large numbers of unhandled exceptions, and both divisions received pages when our job queue was unhealthy. (That said, we still continued to page the DevOps escalation no matter what for a time until the Product Engineering escalation was fully staffed.) We also moved our PagerDuty configuration to terraform to make future changes easier and more transparent.
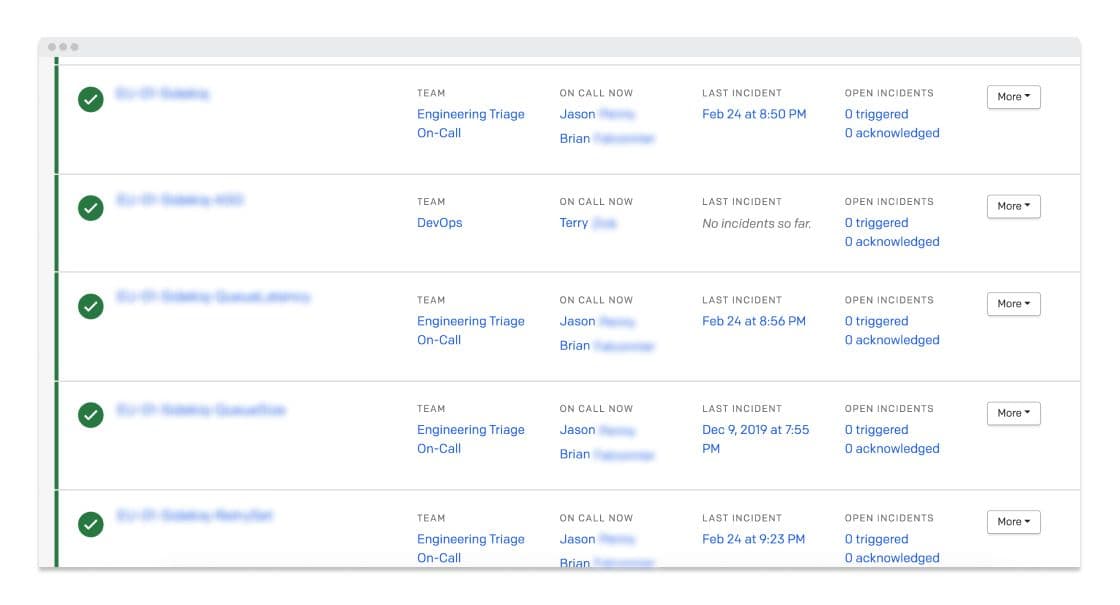
By taking this step, we were able to lay the groundwork for all our future efforts to promote effective page triage and recurrence prevention.
Step Four: Getting the Team Ready to Go On-Call
To move forward, our next step was defining a rotation of engineers who were ready and able to triage issues in production in response to pages. To make that happen, we knew we needed to effectively staff the rotation, provide relevant training and enablement, and iterate quickly to incorporate feedback on this major workflow change.
As we separated out the pages that were being sent, we made it a priority to ensure that every page had a runbook associated with it and that training and permission protocols were set up properly. We’d assumed going into this process that having a proper set of runbooks would be essential, making it possible to triage most production issues by any engineer with access to them. But while the runbooks were useful to write, we found that:
- Most simple runbooks were already automated—and there’s no reason to use people for something that a computer can do
- Pages that didn’t have automatable runbooks tend to be caused by complex issues and will need quick resolution to allow our massively scaled, high-performance system to maintain our SLOs; this means that the problems faced in these situations were too complex to allow us to write runbooks that could be followed in any reasonable timeframe
Beyond the difficulties we found in creating simple runbooks for most pages, we also found that the majority of the pages we received were essentially the type: Something somewhere wasn’t working fast enough and our queuing system was getting backed up. It quickly became clear that triaging pages was a skill that needed to be taught, as most teams didn’t currently possess the knowledge to tackle these operational issues.
Given that, we decided to start with one group of engineers working on a single monolith rotation. Our plan was to train those engineers on the core skills needed to diagnose issues across a massively distributed system and resolve them in a timely manner—then rotate in new engineers and prepare them via documentation, shadowing, and live training.

The next step? Forming the Engineering Triage On-Call and beginning to test our training and enablement processes.
As we actually rolled things out, we found that having an engineer perform real system mitigations during the day, such as disabling or throttling the processing of a live queue, was one of the most valuable pieces of training. These tactics are among the more common steps on the path to a resolution, but it can be hard to prioritize having a trainee run that action when a production issue is in motion—and, worse, frightening for them to have to do it. Practicing the scary steps when things are quiet proved to be very valuable.
Step Five: Going “Live”
We started slow with our new rotation, beginning with a Monday to Friday, eight am to eight pm shift. It was important to us that we didn’t start with a 24/7 approach because we knew that there would likely be aspects of our plan that needed improvement and that would create noise while we iterated. To allow us to take this approach, our ever-patient DevOps team continued to partner with us on every page.
As Product Engineering received our first page, we made weekly improvements to our tooling for monitoring and triaging issues in production. Our Incident Management dashboard also got a series of iterative improvements that enhanced visibility and usability for our team, including:
- Creating a Slack channel where any featuring flipping associated with the Braze platform was logged, making it easier to debug issues from recent state changes
- Automating a Slack post whenever action was taken using our internal incident management tool, providing quick visibility into the actions that had been taken by previous engineers
We also undertook a concurrent effort to completely overhaul our roles, responsibilities, and processes for handling these sorts of incidents. By implementing formal Incident Commanders and Communication Liaisons, retros for all incidents, and regular check-ins on action items associated with pages, we found that the incidents that did occur ran more smoothly, had better outcomes, and saw follow-ups handled more reliably.
Step Six: Reducing Pages
As the Product Engineering team worked toward 24/7 ownership of relevant pages, we also prioritized doing what we could to reduce pages as much as possible. To ensure that we had clear, cross-team communication around the pages that were coming in, we took a couple key steps.
Tracking Pages with JIRA
With each page we received, we made a point of logging it into a JIRA board created for that purpose. The board documented the five stages of response to a page: receipt of a new page, root cause analysis, follow-ups underway, follow-ups complete, and incidents complete.
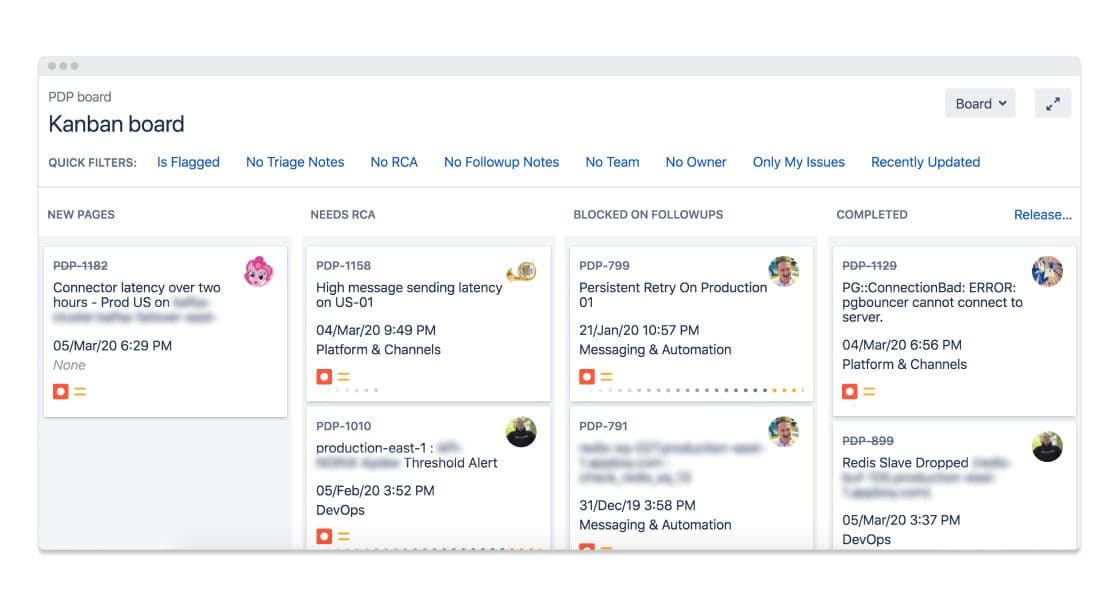
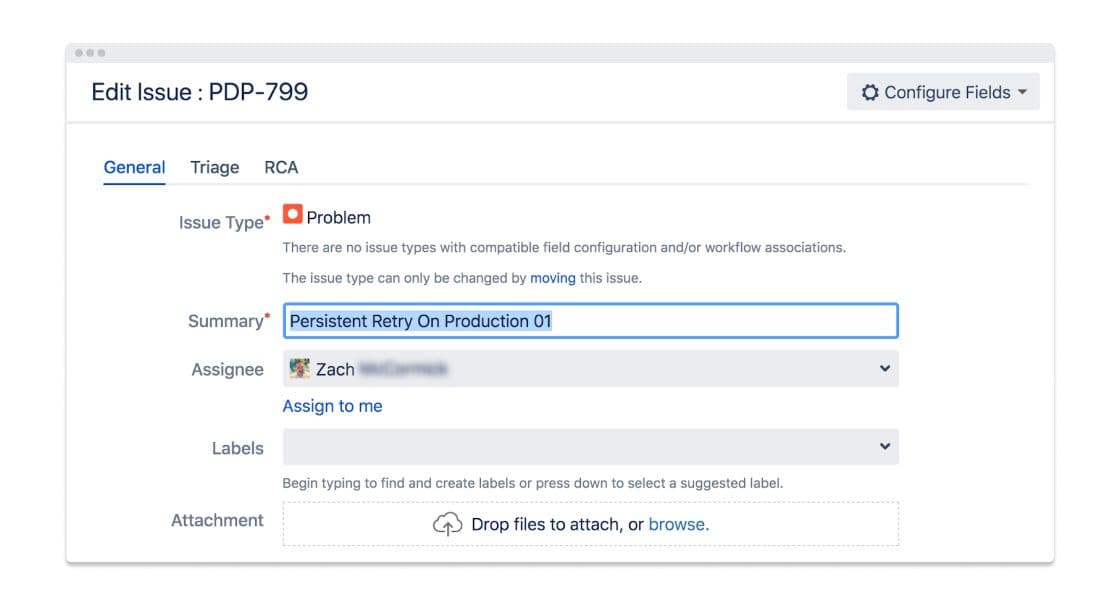
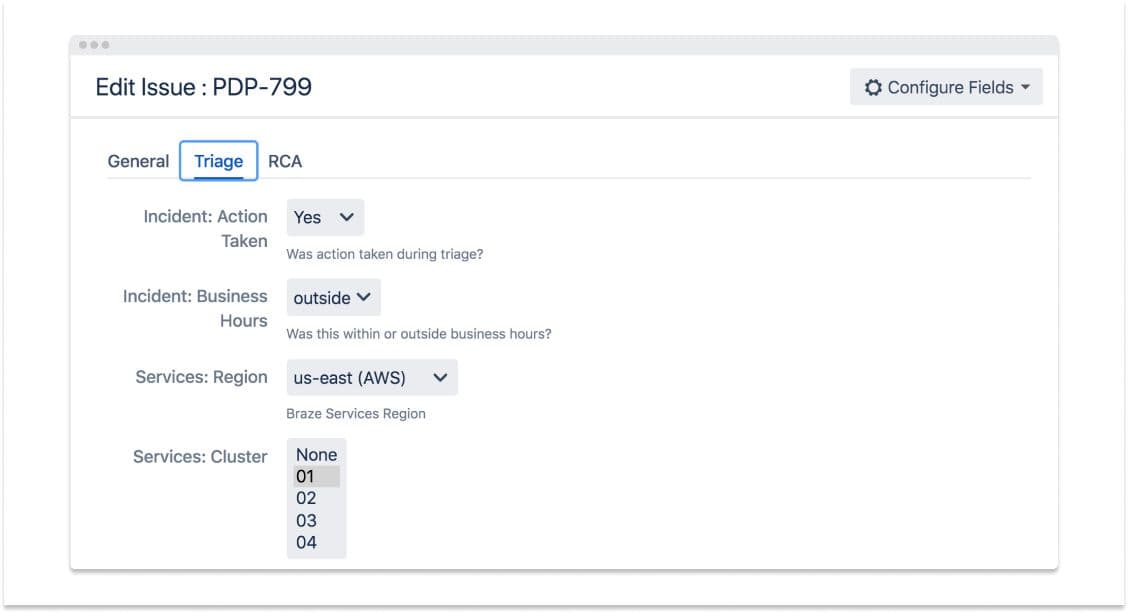
Under our new process, a card was required to stay on the board until the underlying issue associated with that page had been fixed. That could mean fixing a bug, altering the page configuration, or releasing a performance enhancement.
Reviewing Pages in a Daily Meeting
To ensure that follow-ups were being handled, we set up a daily meeting to review the pages that were coming in and the steps that were being taken to address them. The meeting included a rotating group of stakeholders from across the engineering team, ensuring that we had the collective knowledge needed to determine root causes, advocate for next steps, and handle follow-ups efficiently.
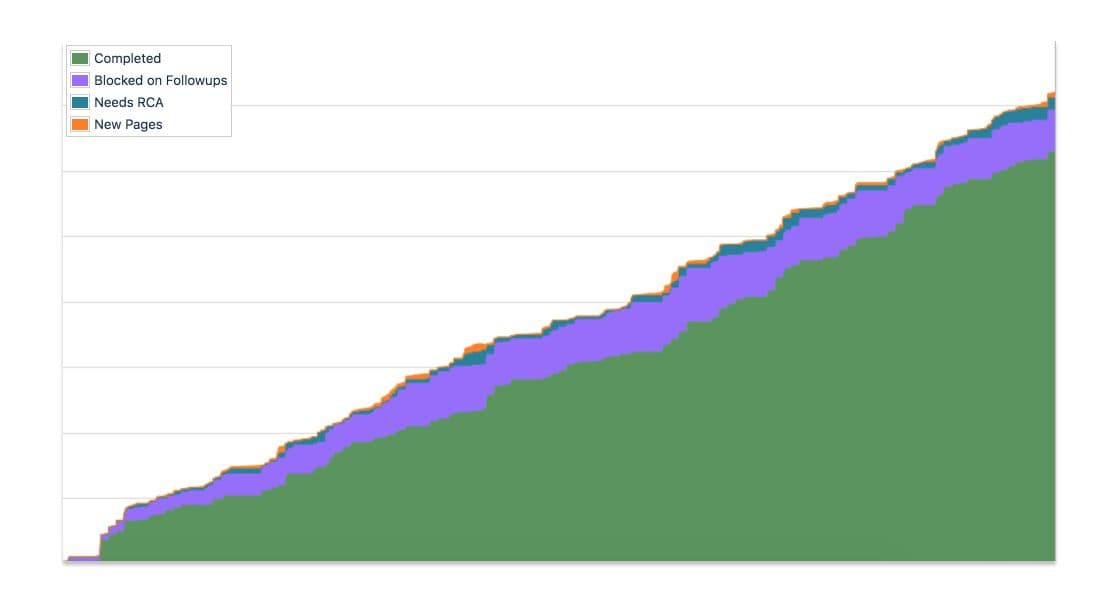
This effort has been paying off. Since starting these programs, we’ve seen our page volume decline even as we’ve been adding more teams and more services to the mix. By tracking pages in the system we use for our core workflow as a Product Engineering team, we were able to deeply integrate them into existing workstreams. Having a best-in-class process for triaging and resolving the causes behind pages enables all teams to better understand the issues affecting our system and take preventive measures—and having this daily meeting with the right mix of people made it possible to follow this process effectively.
Step Seven: Going 24/7
Once we reached that point, we decided we were as ready as we were going to be to roll out a 24/7 Product Engineering rotation. The critical next step we had to undertake was determining who would staff our “off-hours” rotation. We decided we’d try to staff it on a volunteer basis and then take additional steps if that wasn’t sufficient; thankfully, we were able to get a quorum of volunteers, making it possible to go live with 24/7 on-call coverage.
The first week was a bit rough. For one thing, it turned out that some pages that were calibrated for normal work hours didn’t need to fire as frequently as they were set up to. But we made changes in the page review meeting nearly every single day, and by the second week of the off-hours rotation, we found that things were totally manageable.
Final Thoughts
As we look ahead, the Braze Product Engineering team will continue to focus on iteratively improving our process and our applications in production. At the same time, we’ll be starting the march toward ensuring that our code is more cleanly separated into pieces that can be independently tested, deployed, and supported.
Thinking about reworking your paging approach? Learn from our experience with these key takeaways:
- Using a cross-team committee to oversee the process ensures that you get the best input on changes and that others in the organization have people they can consult on the state of things
- Creating a page board can be transformational, making it possible to quantify the risk in your system and prioritize follow-ups more effectively—and having a regular page review meeting is necessary to ensure that the page board is used efficiently
- Continually improving and automating the page process compounds overall effectiveness and saves a lot of time and effort in the long run
Looking to join the Braze Engineering team? Check out our open positions here.
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.
Related Content
 Article3 min read
Article3 min readJuly 2026 Bonfire Marketer of the Month: Cleo’s Holly Jacobson
July 27, 2026 Article8 min read
Article8 min readClosing deals, driving growth for customers, and the team behind it: Life as an Account Executive at Braze
July 17, 2026 Article12 min read
Article12 min readBrazeAI™ marketing tools: The complete guide to AI-powered customer engagement
July 17, 2026