Writing Effective Integration Tests for Asynchronous Workloads
Published on December 06, 2021/Last edited on April 07, 2026/10 min read

Max Gurewitz
Senior Software Engineer, BrazeContents
Integration testing for asynchronous workloads can be complex due to timing issues, external dependencies, and backward compatibility concerns. This guide outlines the Braze approach to architecting robust tests that ensure reliability, accuracy, and maintainable code for asynchronous systems.
When a software company’s business and software achieves a sufficient degree of complexity, it’s inevitable that it will need to find a way to effectively process asynchronous workloads. These workloads will frequently be handled by an asynchronous job processing framework, like Ruby’s Sidekiq, Python’s Redis Queue (RQ), workers that pull messages off of RabbitMQ, or working with an AWS Lambda function that reads from Amazon Simple Queue Service (SQS). But while this need frequently arises, developers often lack experience architecting effective integration tests for these asynchronous workloads.
Here at Braze, we’ve written integration tests for our asynchronous workloads for a number of years. Over time, we’ve learned a lot about how to approach this key need in thoughtful ways that fit our architecture and support our engineering efforts as a whole. Based on those learnings, we will:
- Look at how to write your tests to ensure that your background jobs updates are backwards compatible.
- Consider the dangers of using marshalling as a job parameter encoding.
Let’s dig in.
Common Challenges Associated With Testing Asynchronous Workloads
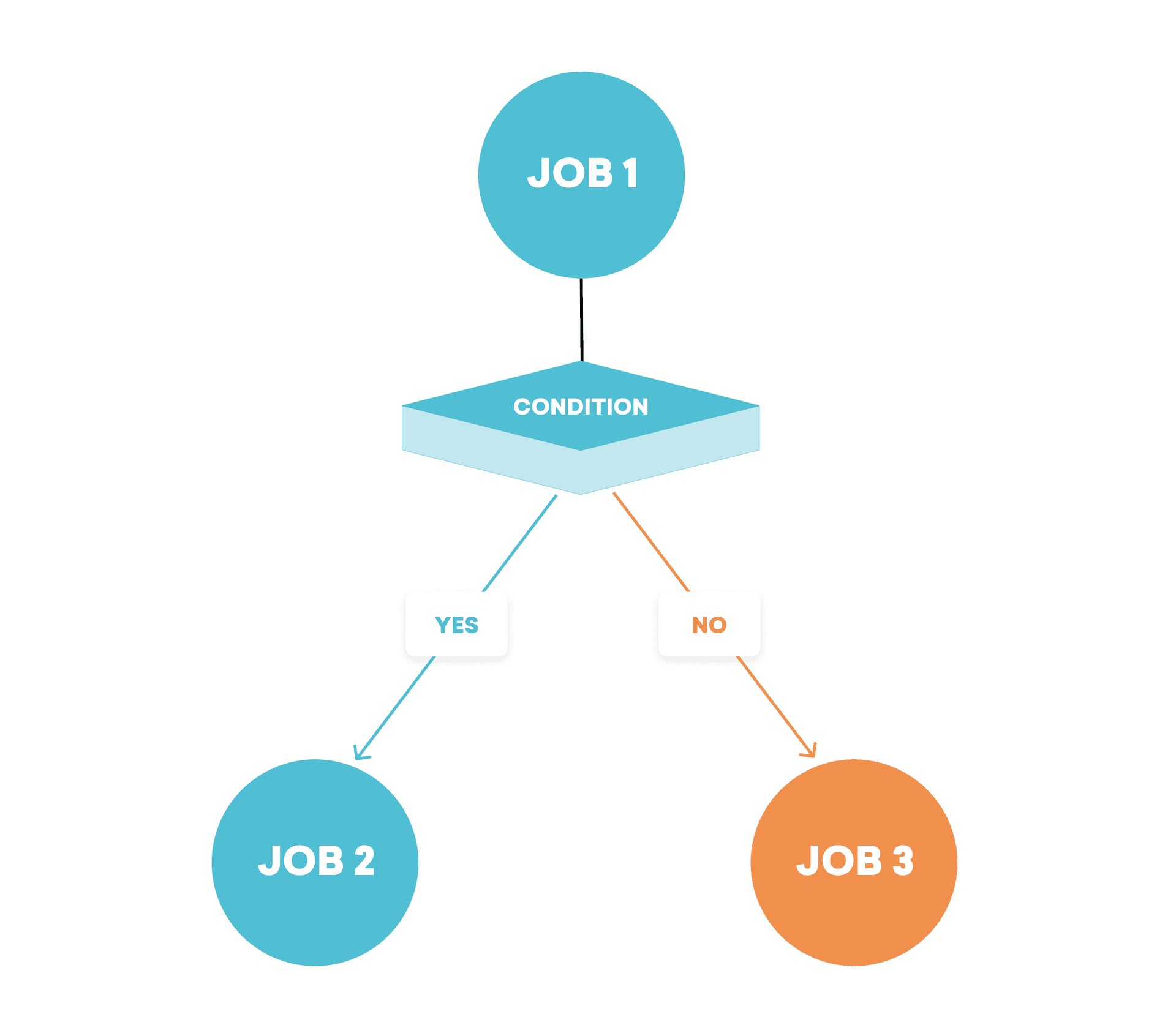
1. Multi-Step Workflows
As a rule, asynchronous jobs aren’t usually run in isolation. Instead, they tend to be composed into a graph of jobs that are then executed in sequence. In this context, unit testing the behavior of a single job won’t necessarily tell you much. It’s more effective to test the end-behavior of that entire workflow of jobs with an integration test.
2. Asynchronous Expectations
The process of writing tests that assert against the behavior of a synchronous API—such as an HTTP server—tends to be fairly straightforward: You pass the API parameters, then you assert that the response has some particular set of characteristics. However, this option isn’t available when you’re testing an asynchronous API, such as a job processor, which can make for a more complex, challenging process.
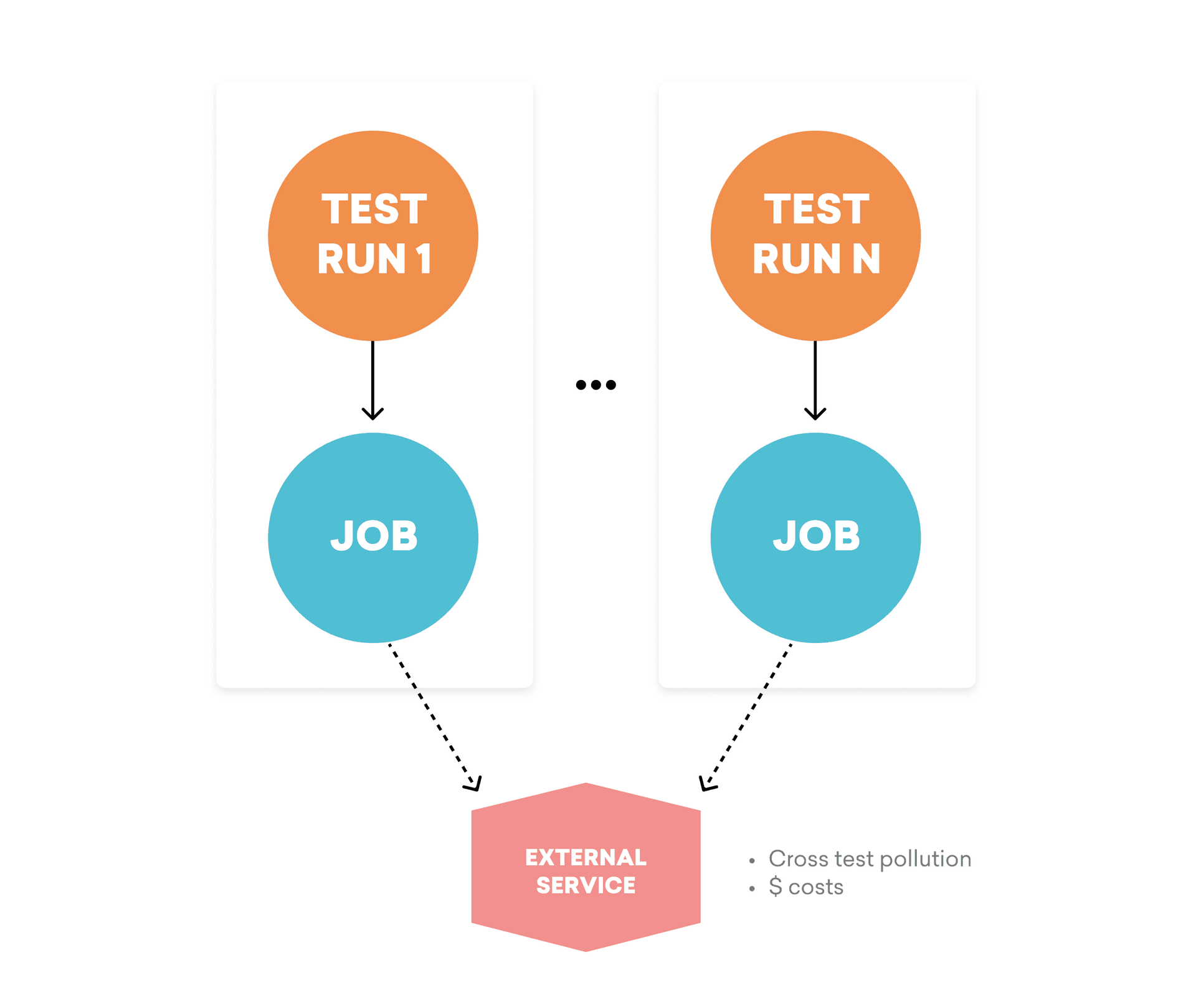
3. External Dependencies
In many cases, asynchronous workloads require access to external, third-party services to function as intended. However, contacting these services within tests can lead to issues. For one thing, they can introduce non-determinacy into your tests by causing cross-contamination of test results. It can also be unsafe to test against a real external service, if—for example—that service’s API produces side effects that shouldn’t be triggered outside of production. On a practical level, it’s also worth keeping in mind that external services can be expensive, so using them for tests may result in unwanted, wasteful costs.
An additional complication? Because we’re writing an integration test that will involve more than one process, it isn’t possible to use traditional stubbing strategies that leverage libraries like Ruby’s RSpec, Python’s unittest, Javascript’s Jest, or Java’s Junit, among others.
Challenges Associated With Testing Asynchronous Workloads at Braze
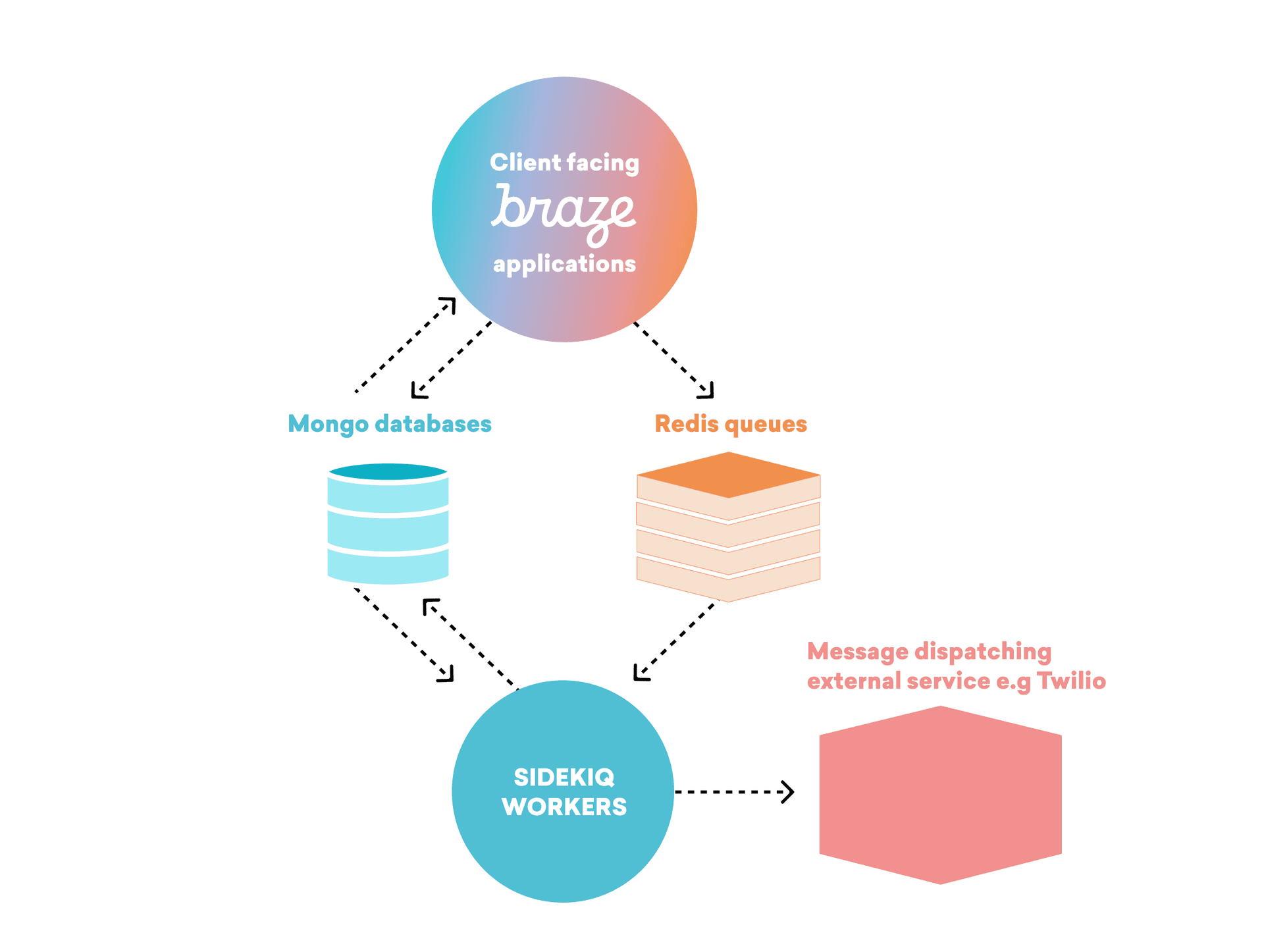
While the above list of challenges isn’t exhaustive, it does cover several key challenges that Braze has faced when it comes to testing our core messaging pipeline.
At Braze, we run jobs enqueued in Redis on Sidekiq workers and one of the main responsibilities of these jobs is to dispatch messages (e.g. email, SMS) to our customer’s users, using external services like Twilio or Sparkpost. Each job conditionally enqueues the next job in a sequence, which can ultimately produce one or more dispatched messages. When it comes to assessing the end-behavior of these jobs, we’re looking for our tests to assert against the number and content of the requests made by our jobs to these external services.
What It Takes to Architect Tests on Asynchronous Workloads
At Braze, we’ve found that it is possible to write effective integration tests for our asynchronous workloads by including the following components.
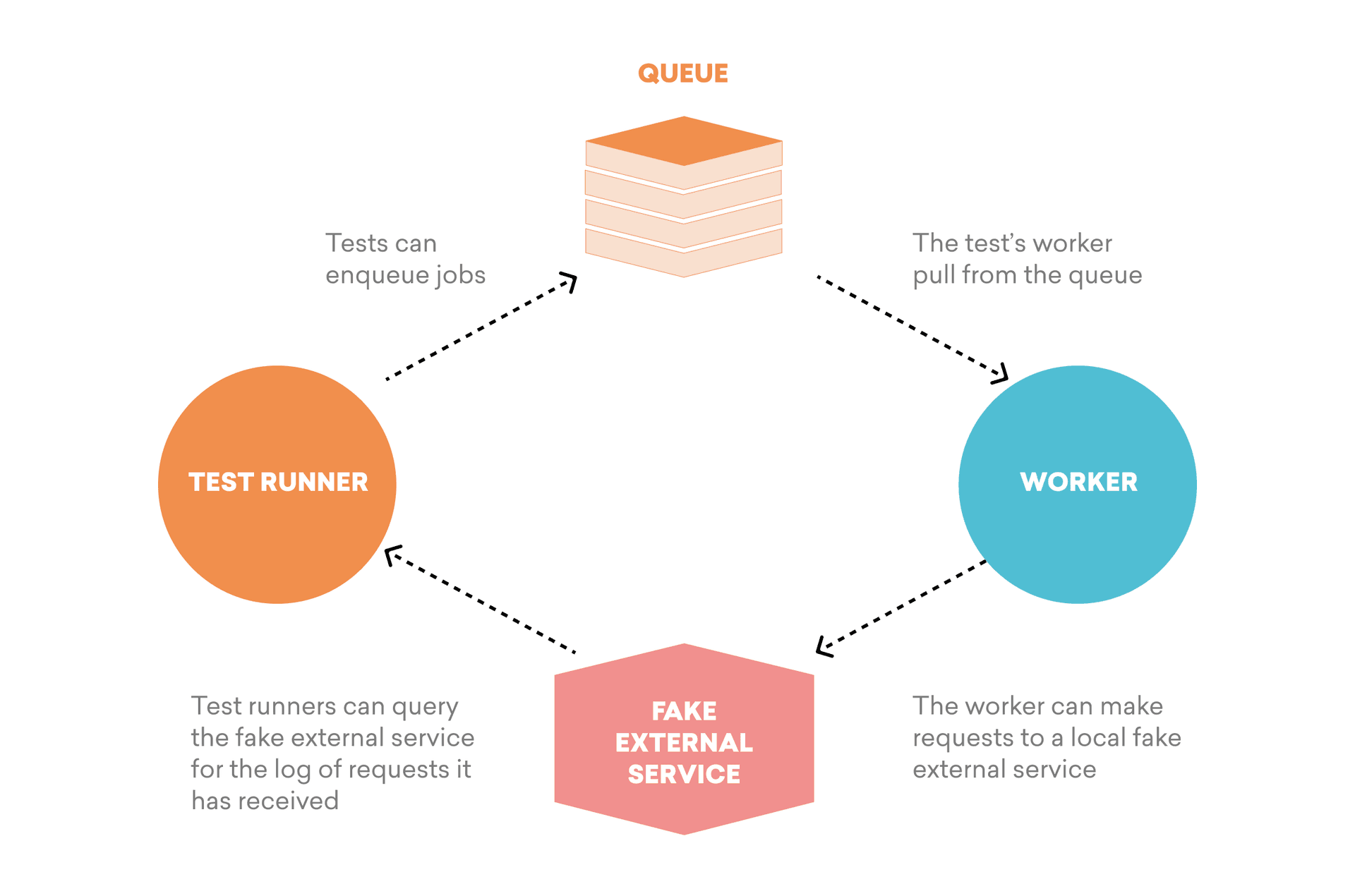
1. Queues
As part of this process, you’re going to need a queue that you’ll use to enqueue jobs that perform the desired behavior you’re trying to carry out. At Braze, this would be a Redis instance, but depending on your setup, it could be something else, like a RabbitMQ application; alternately, if you’re using a proprietary technology like SQS, you could potentially leverage an open source alternative if it provides a compatible interface (e.g. ElasticMQ).
2. Workers
To carry out your test, you’re going to need to run a worker, which will listen in on your job queue. This worker will contain the code that you’re ultimately looking to test; at Braze, for instance, we’d use a Sidekiq worker in this situation.
3. Fake External Service Dependencies
In some cases, you may find that it’s beneficial—or necessary—to fake out your external service dependencies, rather than actually calling on them as part of your integration tests. You can make that happen by writing an application which reproduces the minimal API needed to match your worker’s use case, but with a simplified implementation. This fake API will keep a log of incoming requests; all you need to do then is expose this log by some means e.g. via an http endpoint to be queried and asserted against.
For Braze, this component is a critical part of our testing strategy, in large part because the end-behavior that we’re testing involves the requests we make to external services like Twilio. To make this work, we’ve created a fake API capable of abstracting over these services and then exposing the requests it has received on a dedicated “/request-log” endpoint.
4. Test Runners
In general, you’re also going to need a dedicated process for running your tests, which we will refer to as a “test runner”. These tests will enqueue jobs in your queue, and can then poll the request log of your faked external services (or your workers’ data stores) to assert that the worker has produced the desired side effect within a given timeout period. At Braze, these tests enqueue jobs in Redis, then poll our /request-log endpoint, asserting that we’ve attempted to contact users within a few seconds of the tests’ start.
(It’s also useful to import your job libraries into your test runner, so your tests can perform jobs synchronously as needed.)
5. Other Application Dependencies
Beyond these components, you’ll need to run any internal applications that the worker in question depends on; this will likely include some form of data store. At Braze, these tests run data stores like MongoDB and Memcached.
One Common Issue: Backward Incompatible Job Updates
While there are a number of possible issues that can crop up in connection with asynchronous job processes, one of the most common failure modes—at Braze and elsewhere—is unintentional backward incompatible changes that are made to your jobs’ parameters.
When you’re modifying a job’s parameter, it’s normal for some jobs to remain enqueued in the older format for a period of time, resulting in a mixture of job parameter formats within the queue. Given that, these jobs need to be implemented in a way where workers are capable of accepting parameters in both the new and old format for some time in order to avoid issues.
The upshot? It’s very easy to unintentionally introduce a backward incompatible change into your jobs’ parameters if you aren’t thoughtful and consistent about your testing.
Marshalling and the Risk of Backward Incompatibility
Marshalling is a commonly used in-memory encoding format. It is typically used out of convenience, as it’s very easy to encode complex data structures with marshalling that might otherwise require additional labor to encode in a different format. However, this convenience comes at a cost.
As a rule, marshalling ties your encoding format to the structure of your application’s code, which can potentially create issues. Imagine that you need to upgrade an externally maintained library within your worker, or upgrade your worker’s language version and its standard library. If the internal implementation details of one of those libraries changes, resulting in objects that can’t be marshalled and unmarshalled across library versions, one effect of that change will be that it breaks your worker’s backward compatibility (i.e. causing it to be unable to process jobs issued in the previous format, or enqueue jobs in a format which can be processed by the previous worker version).
Unless you’re intimately familiar with the implementation of every library whose objects get marshalled, it can be very difficult to anticipate which library upgrade will cause backward compatibility issues. Given that, it’s a generally good idea to avoid marshalling altogether by default when it comes to encoding payloads.
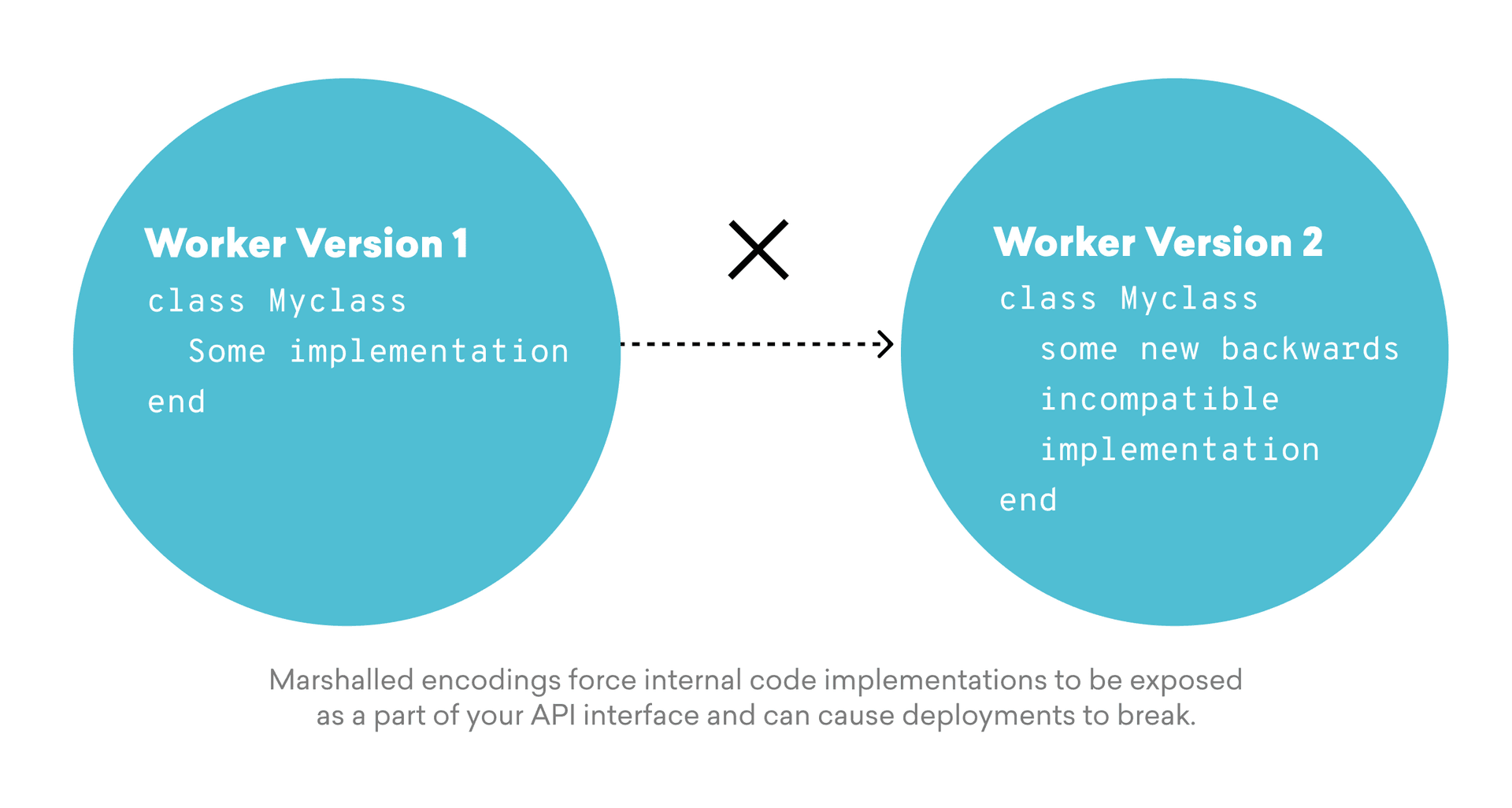
At Braze, we currently use Ruby marshalling to encode Ruby objects within its job parameters and we’ve learned the hard way that marshalling for job parameter encoding can elevate the risk that we’re introducing backward incompatibility. In our case, we experienced this problem while attempting to upgrade Mongoid, an object-document mapper (ODM) that provides Active Record-like functionality for MongoDB within Ruby applications. As it turns out, Mongoid fails to marshall and unmarshall models across versions 6 and 7 under some conditions, introducing an unexpected backward incompatibility.
(One additional note: Ruby on Rails currently uses marshalling to encode its cache payloads, which makes it prone to issues like the ones mentioned above.)
Testing Backward Compatibility
It’s possible to successfully test the backward compatibility of parameter changes by enqueuing job parameters encoded in both the new and old format. Once you’ve done that, you can then verify that your worker is processing the job in both formats correctly.
Minimizing Marshalling Complications
The introduction of a marshalled job parameter encoding will complicate the process of testing the backward compatibility of your job parameter changes. Marshalling can tie your job parameter format to the structure of arbitrary elements of your application’s code base; accordingly, you’ll need to use entirely different application artifacts across test runs to effectively vary a marshall-encoded job parameter format.
At Braze, we used Docker Compose (and its support for environment variables) to run one set of tests on a Docker image which had installed Mongoid 6, and another in connection with Mongoid 7. Taking this approach made it possible for us to reproduce the decoding errors we encountered during our initial product Mongoid upgrade attempt—and then to subsequently fix our test and safely upgrade Mongoid to version 7.
Putting It All Together
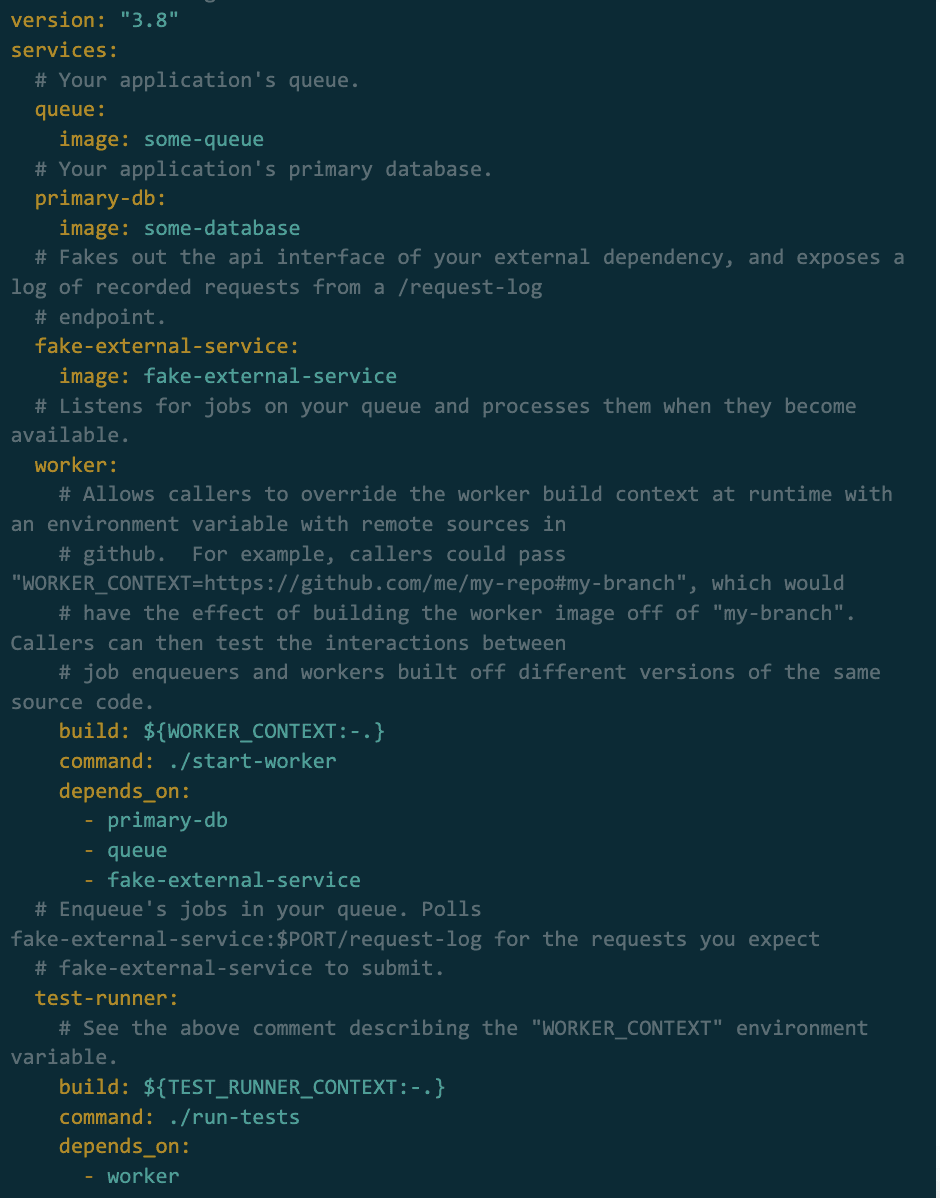
In summary, we’ve covered a number of topics related to supporting integration tests for asynchronous workloads. We’ve covered the basics of how to run these tests and their dependencies, how to test jobs interactions with external service dependencies, and finally how to perform cross-version testing. See the following docker-compose pseudocode for an example of how this all might come together.
Final Thoughts
As asynchronous workloads become increasingly common, knowing how to carry out effective tests is only becoming more important. By understanding common failure modes and what it takes to architect workable tests, you can minimize the chances that your jobs become backward incompatible, and iterate on your jobs more confidently with fewer fears of regressions.
Interested in learning more about Braze or gaining firsthand experience with our technology and architecture? Check out our open roles.
Related Tags
Be Absolutely Engaging.™
Sign up for regular updates from Braze.


