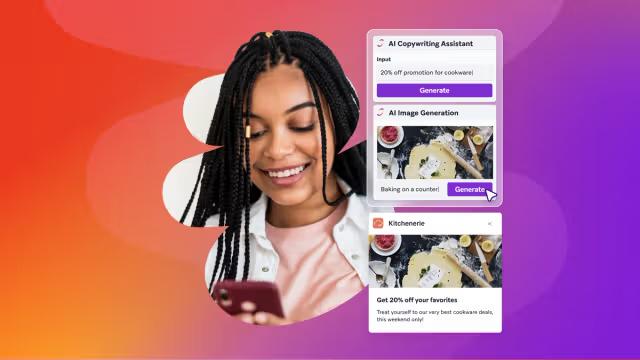
De las pruebas multivariantes a la toma de decisiones con IA
Publicado en 30 de septiembre de 2025/Modificado por última vez el 30 de septiembre de 2025/7 min de lectura


Victor Kostyuk
Responsable de Engineering, AI Decisioning and RL, BrazeLas pruebas A/B son demasiado lentas, así que te has pasado a las pruebas multivariantes: en lugar de probar dos variantes al mismo tiempo, pruebas muchas variantes a la vez. Las pruebas multivariantes son, en efecto, más rápidas que las pruebas A/B, pero, por lo demás, tienen todas las desventajas de las pruebas A/B: son más rápidas, pero siguen siendo demasiado lentas; no se adaptan a los cambios de comportamiento del cliente; y no están personalizadas para cada cliente. Hay una forma radicalmente mejor de optimizar tus campañas de marketing: la toma de decisiones con IA mediante bandits contextuales.
En este post, explicamos la evolución de los métodos de experimentación en marketing, desde las pruebas A/B a las pruebas multivariantes, pasando por los multi-armed bandits y los bandits contextuales. Describimos las ventajas de cada método sobre su predecesor, así como los inconvenientes de cada enfoque. Por último, presentamos la forma en que Braze utiliza y mejora los bandits contextuales para conseguir una verdadera personalización 1:1.
Pruebas multivariantes
En las pruebas A/B, comparas dos variantes asignando aleatoriamente la mitad de tu audiencia de clientes a cada variante, enviando el mensaje de marketing correspondiente y comparando el rendimiento de las variantes según tu métrica de resultados, por ejemplo, la tasa de conversión. Digamos que quieres saber qué zapato incluir en una oferta por correo electrónico.
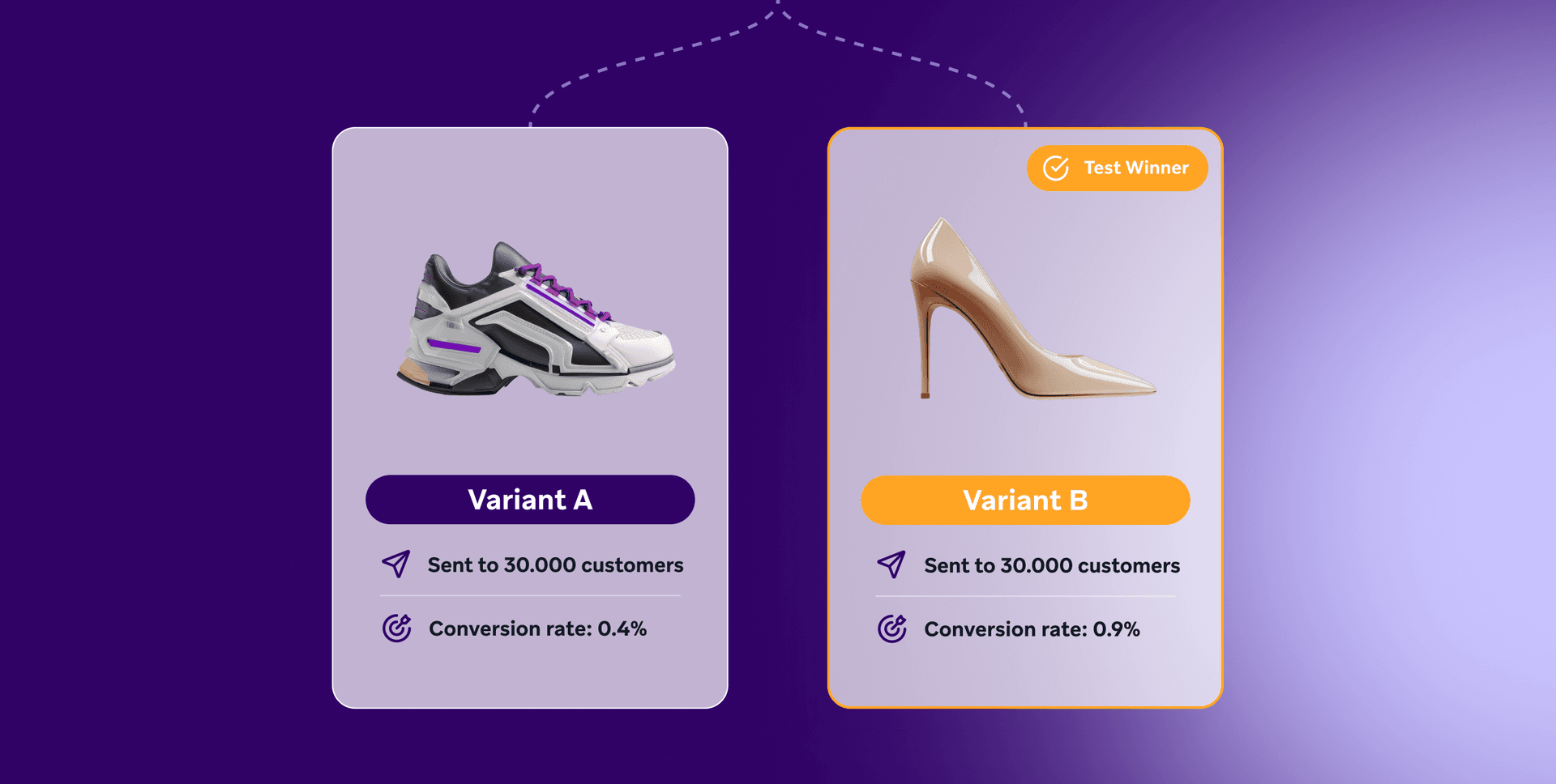
Tienes más de 2 zapatos que puedes ofrecer, así que con un enfoque de pruebas A/B, tienes que seguir probando más zapatos entre sí, un proceso muy lento y tedioso. Con las pruebas multivariantes, puedes probar todas tus variantes a la vez:

Las pruebas multivariantes son esencialmente pruebas A/B realizadas en paralelo en lugar de secuencialmente. Este enfoque paralelo ofrece un ahorro de tiempo significativo respecto a las pruebas A/B tradicionales, ya que puedes probar múltiples variables simultáneamente en lugar de ejecutar pruebas separadas una tras otra.
Sin embargo, esta eficacia tiene una contrapartida. Como toda la audiencia se divide en partes iguales entre todas las combinaciones de variaciones (2 géneros x 3 estilos = 6 combinaciones en el ejemplo anterior), puede ser difícil alcanzar la relevancia estadística si hay muchas combinaciones.
Para los especialistas en marketing, esto plantea un dilema:
- Esperar más tiempo para recopilar datos suficientes que garanticen que los resultados son fiables (señal) y no meras fluctuaciones aleatorias (ruido).
- Actuar con rapidez para aplicar lo que parece ser la mejor opción basándose en los primeros datos, potencialmente poco fiables.
Cuantas más combinaciones pruebes, más pequeño será cada grupo, lo que agravará este reto. Por ejemplo, si tienes 60.000 clientes y pruebas 6 combinaciones, cada combinación sólo se prueba en 10.000 clientes. Si aumentas a 12 combinaciones, te quedas en 5.000 clientes por combinación, lo que hace aún más difícil alcanzar la relevancia estadística en un tiempo razonable.
Debido a estas limitaciones, las pruebas multivariantes suelen utilizarse para un pequeño subconjunto de variaciones que el especialista en marketing desea probar, en lugar de para todas las combinaciones posibles de textos de marketing o productos. Esto ayuda a mantener grupos de mayor tamaño y a alcanzar la relevancia estadística más rápidamente, pero reduce la cantidad de variantes probadas y, por tanto, la utilidad de la técnica.
Otra limitación crucial de las pruebas multivariantes es su naturaleza estática. Una vez que hayas realizado la prueba y determinado un "ganador", ese resultado es fijo. Sin embargo, las preferencias y los comportamientos de los clientes cambian con el tiempo. Una variante que rinde bien hoy puede no ser la mejor opción dentro de uno o dos meses. Las pruebas multivariantes tradicionales no tienen en cuenta estos cambios a menos que realices continuamente nuevas pruebas, lo que puede llevar mucho tiempo y consumir muchos recursos.
En esta situación es donde brillan métodos más avanzados como los multi-armed bandits y los bandits contextuales.
Multi-armed bandits (MAB)
Como las pruebas multivariantes dividen a la audiencia por igual entre distintas variantes, el experimento puede ser bastante ineficaz en cuanto a maximizar las conversiones. Cada variante se envía al mismo número de clientes (10.000 en el ejemplo anterior), aunque en los primeros 1.000 envíos quede claro que una variante es mucho peor que otra. Un multi-armed bandit (MAB, por sus siglas en inglés) es un algoritmo que asigna eficazmente los envíos a cada variante en función de la probabilidad de que esa variante sea la mejor. Así, un MAB es mucho más eficaz para dar con la mejor combinación que una prueba multivariantes. Esto no significa que el MAB sólo envíe la variante que considera mejor en ese momento: los MAB equilibran la explotación, enviando la variante que estima que es mejor en ese momento, con la exploración, enviando otras variantes para mejorar su estimación.
Esto apunta a otra ventaja de un MAB sobre las pruebas multivariantes: un MAB experimenta continuamente. Se dará cuenta de si, con el tiempo, una variante que al principio tenía un rendimiento bajo tiene más éxito luego, y empezará a enviar esa variante con más frecuencia, proporcionalmente al aumento de rendimiento de esa variante. Así, la variante que un MAB considera mejor y la distribución de variantes que envía pueden cambiar con el tiempo.

Los MAB son excelentes para encontrar al ganador global, es decir, la variante con mejor rendimiento para toda una población de clientes o un segmento, y ajustarse a medida que el "ganador" cambia con el tiempo. Pero los MAB tienen una limitación fundamental: no son capaces de personalizar. Un MAB trata a cada variante con la que experimenta como una caja negra (por ejemplo, no sabe si un zapato es parecido a otro, por lo que es más probable que tengan un rendimiento similar) y también a todos los clientes por igual. Sin embargo, ¡ni los clientes ni las variantes son todos iguales!
Bandits contextuales
A diferencia de los MAB, los bandits contextuales son algoritmos que utilizan el contexto sobre los clientes, las variantes y el entorno (por ejemplo, «¿hoy es festivo o fin de semana?») para tomar decisiones. Por ejemplo, el bandit contextual sabría cuál es el estilo de un zapato y si es de hombre o de mujer. Este bandit también conocería el historial de compras del cliente (qué estilos de zapatos ha comprado en el pasado). Esto permitirá al bandit contextual aprender rápidamente qué ofertas pueden funcionar con qué clientes.
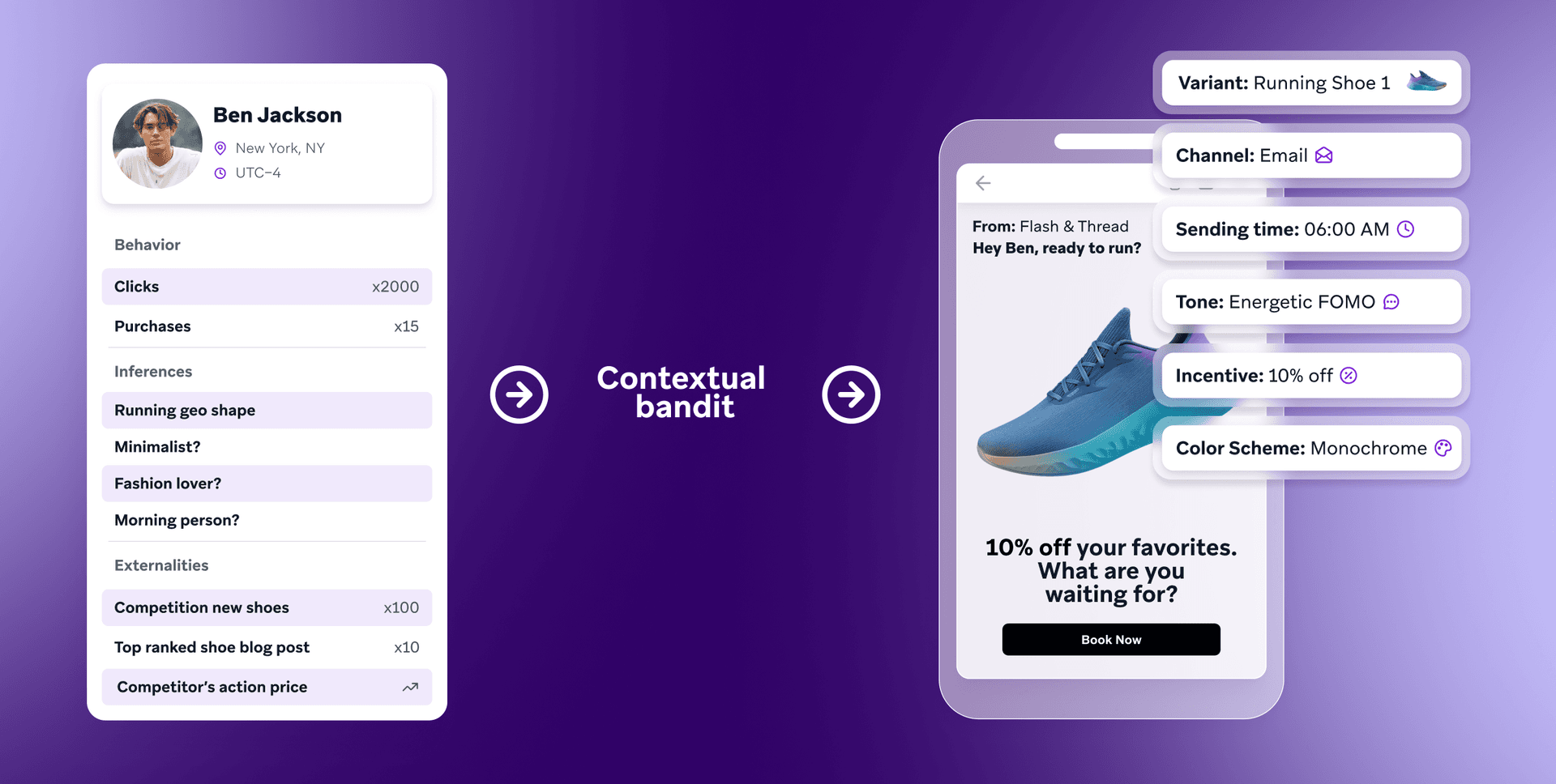
El bandit contextual no se limita a seleccionar una variante basándose en la probabilidad promedio de que esa variante logre la conversión, sino en la probabilidad de que lo haga un cliente concreto en un entorno determinado (por ejemplo, un sábado por la mañana).
Además, el bandit contextual es capaz de generalizar entre variantes. Por ejemplo, si se lanza una nueva zapatilla de correr y se añade como opción, el algoritmo utilizará el hecho de que su estilo es "zapatilla de correr" y aprovechará los aprendizajes sobre zapatillas de correr para recomendar la nueva zapatilla. Por lo tanto, es mucho más aplicable a los casos de uso de marketing, en los que aparecen nuevas variantes continuamente.
Los bandits contextuales tienen desventajas: son más complejos de implementar y mantener que los MAB, requieren datos actualizados sobre los clientes y, si bien son capaces de manejar un conjunto de variantes mucho mayor que los métodos anteriores, siguen viéndose ralentizados por las grandes colecciones de variantes.
Toma de decisiones con IA: cómo Braze utiliza y mejora los bandits contextuales
Para aumentar la eficacia de una muestra, es decir, la rapidez con que el modelo aprende a partir de datos limitados, en Braze utilizamos una "comunidad de bandits", que son agentes de decisiones con IA que dividen la recomendación en distintas dimensiones (por ejemplo, día de la semana, hora del día, canal, creatividad, oferta), con un bandit contextual distinto que toma decisiones en cada una de estas dimensiones.
Para saber más sobre la toma de decisiones con IA, consulta el informe sobre nuestra comunidad de bandits.
Etiquetas relacionadas
Logra el máximo atractivo.™
Regístrate para recibir actualizaciones periódicas de Braze.